I riassunti , gli appunti i testi contenuti nel nostro sito sono messi a disposizione gratuitamente con finalità illustrative didattiche, scientifiche, a carattere sociale, civile e culturale a tutti i possibili interessati secondo il concetto del fair use e con l' obiettivo del rispetto della direttiva europea 2001/29/CE e dell' art. 70 della legge 633/1941 sul diritto d'autore
Le informazioni di medicina e salute contenute nel sito sono di natura generale ed a scopo puramente divulgativo e per questo motivo non possono sostituire in alcun caso il consiglio di un medico (ovvero un soggetto abilitato legalmente alla professione).
Il software non è solo un insieme di linee di codice ma comprende anche tutta la documentazione, i case test ed i manuali.
Il software implementa una macchina che deve interagire con l’ambiente esterno.
Gli ingegneri del software devono essere capaci di capire ed analizzare gli ambienti esterni.
Gli ambienti esterni sono il posto dove trovare i requisiti.
I prodotti generici sono dei software prodotti da aziende e utilizzati da un ampio bacino di utenza diversificato. I prodotti specifici sono software sviluppati ad hoc per uno specifico cliente, visionato dallo stesso. La fetta maggiore della spesa è nei prodotti generici ma il maggior sforzo di sviluppo è nei prodotti specifici.
Un programma è una semplice applicazione sviluppata, testata e usata dallo stesso sviluppatore. Il prodotto software viene sviluppato per terzi, è un software industriale che ha un costo di circa 10 volte superiore ad un normale programma e deve essere corredato di documentazione, manuali e case test.
L’approccio singolo non è scalabile per grandi progetti.
Il costo del software viene calcolato in base alle ore di lavoro (manpower), al software e all' hardware utilizzato e altre risorse di supporto. Il costo (espresso in mesi/uomo) della manutenzione è superiore a quello di produzione.
Il software dopo il suo rilascio, specie se lo stesso ha una vita lunga, ha bisogno di alcune fasi di manutenzione. Per manutenzione intendiamo sia la correzione di eventuali bug, sia l’estensione/modifica di alcune caratteristiche. Il costo della manutenzione è più elevato rispetto a quello di produzione.
Disciplina che cerca di fornire le regole per il processo di produzione del software. Lo scopo dell’ingegneria del software è di pianificare, progettare, sviluppare il software tramite lavoro di gruppo. E’ possibile che vengono rilasciate più versioni del prodotto software. Tale attività ha senso per progetti di grosse dimensioni e di notevole complessità ove si rende necessaria la pianificazione.
Mentre la computer science si occupa di creare e ottimizzare algoritmi e si occupa degli aspetti teorici dell’informatica, il software engineering si occupa della pianificazione e della progettazione con la finalità di ottenere un prodotto software.
L’ingegneria del software si occupa principalmente di tre aspetti fondamentali:
Un metodo è un particolare procedimento per risolvere problemi specifici, mentre la metodologia è un’insieme di principi e metodi che serve per garantire la correttezza e l’efficacia della soluzione al problema.
Uno strumento (tool) è un artefatto che viene usato per fare qualcosa in modo migliore. Una procedura è una combinazione di strumenti e metodi finalizzati alla realizzazione di un prodotto.
Un paradigma è un particolare approcio o una filosofia per fare qualcosa (Stile).
Un processo software è un'insieme organizzato di attività finalizzate alla costruzione di un prodotto da parte del team di sviluppo. Utilizzando metodi, tecniche, metodologie e strumenti.
E' suddiviso in varie fasi secondo uno schema di riferimento (CVS: Cliclo di vita del Software).
Viene descritto da un modello che descrive la maturità del processo: informale, semiformale o formale.
Definizione: Sistemi software che intendono fornire uno sviluppo automatico per le attività di un processo software.
Upper-CASE: Strumenti che supportano le attività delle fase di analisi, specifica dei requisiti e progettazzione di un processo software. ES. Ration Rose, StarUML, etc.
Lover-CASE: Strumenti che supportano le attività delle fasi finali del processo, come programmazzione, testing e debunggin ES. Eclipse
La qualità può essere riferita sia al prodotto che al processo applicato per ottenere il risultato finale.
Un particolare modello di qualità (modello di McCall) dice che la qualità si basa su i seguenti tre aspetti principali:
Occorre capire qual è il ciclo di vita del software e come gestirlo in maniera corretta.
Il ciclo di vita comprende le fasi di produzione a partire da quando si decide di utilizzare un
software e comprende la manutenzione e la dismissione, anche se non tutti i software seguono il
ciclo di vita fino in fondo.
Un processo software è un insieme organizzato di attività finalizzate ad ottenere il prodotto da parte di un team di sviluppo utilizzando metodo, tecniche, metodologie e strumenti.
Il processo viene suddiviso in fasi in base ad uno schema di riferimento (ciclo di vita del software).
E’ una caratterizzazione descrittiva o prescrittiva di come un sistema software viene o dovrebbe essere sviluppato.
Esistono vari modelli di CVS:
• Waterfall (Modello a Cascata)
• Verification & Validation a Retroazione (Feadback)
• Modello a V
• Prototyping (Modello basato su Prototipi)
• Prototipazione Throw-Away (Usa e Getta)
• Prototipazione Evolutiva
• Sviluppo Evolutivo (Incremental delivery)
• Trasformazionale
• Sviluppo a componenti (Basato sul riuso sistematico dei componenti)
• Sviluppo incrementale
• Modelli Incrementali
• Modelli Iterativi
• Spiral model (Modello a Spirale)
Molti aspetti influenzano la definizione del modello:
• specificità dell’organizzazione produttrice
• know-how (conoscere come)
• area applicativa e particolare progetto
• strumenti di supporto
• diversi ruoli produttore/ committente
Le fasi principali di un qualsiasi CVS sono le seguenti:
Il modello identifica le fasi e le attività da svolgere durante il progetto del software. Trae ispirazione
dalle attività ingegneristiche tradizionali.
L’idea è descrivere con chiarezza l’output di ogni fase che diventa l’input della fase successiva.
Definisce che il processo segua una progressione sequenziale di fasi senza ricicli, al fine di controllare meglio tempi e costi. Inoltre definisce e separa le varie fasi e attività del processo in modo da minimizzare la sovrapposizione tra di esse. Ad ogni fase viene prodotto un semilavorato con la relativa documentazione e lo stesso viene passato alla fase successiva (milestore). I prodotti ottenuti da una fase non possono essere modificati durante il processo di elaborazione delle fasi successive (non è possibile tornare indietro).
Si adatta bene quando il sistema da sviluppare non cambia, cioè quando ci sono pochi imprevisti. Per cui risulta poco adatto ai sistemi software.
Effettua una valutazione preliminare dei costi e dei requisiti in collaborazione con il committente. L’obiettivo è quello di decidere la fattibilità del progetto, valutarne i costi, i tempi necessari e le modalità di sviluppo:
• Analisi costi/benefici: Valutazione preliminare dei costi e dei benefici di un’applicazione, per
stabilire se si debba avviarne lo sviluppo, quali siano le alternative possibili, quali le scelte più
ragionevoli, e quali le risorse finanziarie e umane necessarie per l’attuazione del progetto.
• Si sceglie se il prodotto deve essere realizzato oppure comprato, si valutano risorse alternative
• Si produce un documento con lo studio di fattibilità con:
o descrizione dei problemi (necessità dell’utente)
o scenario delle soluzioni possibili (si cominciano ad abbozzare alcune soluzioni tecniche)
o costi per le differenti soluzioni
Qui si decide se andare avanti o meno con lo sviluppo del software.
Output: documento di fattibilità.
• Si analizza il dominio in cui l’applicazione opererà (ambiente, vincoli di natura
tecnologica,…)
• Si identificano i requisiti: si stabiliscono funzionalità (requisiti funzionali), vincoli e
obiettivi consultando gli utenti (tipicamente il committente).
Un modo possibile di descrivere i requisiti funzionali consiste nel fornire una versione
iniziale del Manuale Utente.
• Si derivano le specifiche per il software: richiede un’interazione con l’utente ed una
comprensione delle proprietà del dominio.
• Viene prodotto il RASD (Requirements Analisys and Specification Document) che deve
essere compatto, conciso e consistente
Alcune di queste cose sono già state fatte nella fase 1 con lo studio di fattibilità, ma qui occorre arrivare al massimo livello di dettaglio.
Nella fase di analisi dei requisiti e delle specifiche ci si deve concentrare sui seguenti punti (le 5 w)
• Who (chi userà il sistema)
• Why (perché deve essere sviluppato e perché gli utenti dovrebbero usarlo)
• What vs HOW (cosa apporterà il sistema, e non come deve essere fornita)
• Where (dove sarà usato, su quale architettura)
• When (quando e per quanto tempo sarà usato)
Il RASD: dovrà essere: preciso, completo e consistente e potrà includere un manuale utente
preliminare.
In questa fase viene anche definito il Piano di Test di Sistema (PTS) che descrive le modalità con cui, al termine dello sviluppo, nella fase di integrazione, si possa verificare il sistema sviluppato rispetto ai requisiti fissati.
Anche questo documento andrebbe sottoscritto dal committente
Output: documento di specifica dei requisiti (RASD).
Si definisce la struttura del software e il sistema viene scomposto in componenti e moduli:
• moduli
• relazioni
• interazioni (da cui capisco il comportamento a run-time del sistema)
Si descrivono le funzioni che il sistema deve svolgere, ciascuna delle quali verrà trasformata in uno o più programmi eseguibili; l’obiettivo è scomporre il problema in sottoproblemi in modo da ridurne la complessità
L'architettura software può essere composta da moduli, evidenziando quali siano le funzionalità
offerte dai diversi moduli e le relazioni tra i moduli
Il risultato dell’attività di progettazione è il Documento di Specifiche di Progetto (DSP) nel quale la definizione dell’architettura software può anche essere data in maniera rigorosa, o addirittura formale, usando opportuni linguaggi di specifica di progetto
Output: Scomposizione del sistema in moduli e definizione dei linguaggi e formalismi tramite il Documento di specifica di Progetto(DPS)
Ogni modulo viene codificato nel linguaggio e testato separatamente dagli altri.
Il progetto viene realizzato come insieme di programmi o unità di programmi (moduli).
• Ogni modulo è implementato usando il linguaggio di programmazione scelto
• Ogni modulo è testato singolarmente dallo sviluppatore (in isolamento)
Il testing delle unità serve per verificare che ciascuna soddisfi le specifiche richieste.
Il prodotto è:
• Codice sorgente dei singoli moduli
• Risultati dei test fatti sul codice sorgente (dati di ingresso ed output)
• Documentazione (commenti, scelte tecniche…)
I moduli vengono integrati tra loro e vengono testate le loro interazioni. Viene rilasciata una beta release (release esterna) oppure una alpha release (release interna) per testare al meglio il sistema.
Alfa e Beta test
• Alfa test quando il sistema è rilasciato per l’uso, ma all’interno dell’organizzazione del
produttore
• Beta test quando si ha un rilascio controllato a pochi e selezionati utenti del prodotto
L'output è:
Integrazione dei moduli per comporre il sistema vero e proprio e rilascio di Beta o Alpha
release
Rilascio del prodotto al cliente allo scopo è distribuire l’applicazione e gestire le diverse installazioni e configurazioni tra i vari clienti.
Prima era fatta on site, adesso può anche essere fatta in remoto
La Manutenzione gestisce l’evoluzione del software, comporta la correzione degli errori che non erano stati scoperti nelle fasi precedenti, migliorando la realizzazione delle unità del sistema ed aumentando i servizi forniti man mano che si richiedono nuovi requisiti.
È la fase più lunga del ciclo di vita di un prodotto software (oltre il 50% dei costi complessivi del ciclo di vita). Circa l’80% del budget IT(information tecnology) è speso in manutenzione.
PRECISAZIONI
EVOLUZIONE
Perché un software dovrebbe evolvere? I motivi possono essere molteplici.
• Cambiamenti del contesto (esempio € vs £)
• Cambiamento nei requisiti
• Specifiche sbagliate
• Requisiti sconosciuti in anticipo
TIPOLOGIE DI CAMBIAMENTI:
• Correttivi (software bacato) ~ 20%
• Adattativi (ci si deve adattare a cambiamenti nel sistema o nell’ambiente) ~ 20%
• Migliorativi (per avere delle funzionalità in più) ~ 50%
BUONE ABITUDINI
Prima modificare il progetto, poi l’implementazione applicando le modifiche in modo consistente in tutti i documenti.
COME FRONTEGGIARE L’EVOLUZIONE
L’obiettivo è anticipare i cambiamenti. Il software deve essere generato per rimanere aperto, deve
essere possibile cambiarlo in modo semplice dopo che è stato sviluppato. I cambiamenti devono
essere facilmente realizzabili ed a basso costo.
Non bisogna confondere evoluzione con correzione .
Spesso il software non è stato progettato per essere modificato facilmente, si apportano modifiche
intervenendo direttamente sui programmi, senza modificare, se è il caso, la documentazione di
progetto e di test, la specifica dei requisiti, etc.
Un problema molto sentito dai produttori di software è quello di “recuperare” le applicazioni
esistenti.
La re-ingegnerizzazione del software (reverse engineering) consiste nella possibilità di riportare
software ormai poco strutturato e non documentato in uno stato in cui sia possibile poi ripartire in
modo sistematico nella manutenzione
DATI SUGLI ERRORI
• Ispezioni sistematiche possono trovare fino al 50-75% degli errori.
• Moduli con un controllo di flusso complesso possono facilmente contenere più errori.
• Spesso i test coprono soltanto il 50% del codice.
• Il codice distribuito contiene il 10% degli errori trovati nel testing.
• Gli errori iniziali sono scoperti tardi ed il costo per eliminarli aumenta con il passare del
tempo.
• Eliminare errori da un grosso sistema costa più (4-10 volte) che in un sistema piccolo.
• L’eliminazione di errori introduce nuovi errori.
• I grossi sistemi tendono a stabilizzarsi ad un certo livello di inperfezione.
VARIANTI DEL MODELLO A CASCATA
A volte non servono tutte le fasi:
• software per uso personale
• utente che appartiene alla stessa organizzazione
• applicativi per la vendita sul mercato
Il ciclo a cascata può essere deleterio. Bisogna essere preparati a più cicli di iterazione. Il riciclo
non può essere eliminato.
Il Waterfall model può essere vista come una black
box, in cui inseriamo i requisiti e tramite dei processi, tiriamo fuori il prodotto.
In realtà si vuole un monitoraggio all’interno del processo.
Non voglio solo che il prodotto rispetti le specifiche ma voglio anche un riscontro nelle varie fasi.
Si vuole un feedback per supportare la
flessibilità.
Note:Feedback (testing): il collaudo è una delle questioni fondamentali. E' necessario avere più
codice per il test che per il programma vero e proprio. Ogni programmatore deve scrivere il
programma di test parallelamente se non prima di scrivere il codice effettivo.
PROCESSI FLESSIBILI
Il modello a cascata non va sempre bene, esistono altri modelli più flessibili che servono a tenere
conto fin dall’inizio dei cambiamenti.
L’idea è quella di avere dei processi incrementali in cui ho un feedback ad ogni passo.
Ecco le principali alternative al Modello a cascata:
• Verifica: stiamo producendo il prodotto nel modo corretto?
• Validazione: stiamo producendo il prodotto giusto?
È una verifica rispetto agli input
Simile al modello a cascata, vengono applicati i ricicli, ovvero al completamento di ogni fase viene fatta una verifica ed è possibile tornare alla fase precedente nel caso la stessa non verifica le aspettative. Feedback possono essere inviati ad una qualsiasi delle fasi precedenti.
Le attività si sinistra sono collegate a quelle di destra intorno alla codifica.
Se si trova un errore in una fase a destra si riesegue il pezzo della V collegato.
Più tardi si scopre un errore e più difficile sarà porvi rimedio.
Salta alcune fasi. Si va all’implementazione (prototipo) che non ha tutte le funzionalità richieste al sistema ma solo un sottoinsieme di funzioni ritenute rilevanti.
Si parla di incremental delivery quando si sottopone il prototipo all’approvazione del committente
ad ogni passo, infatti in questo modello il cliente è parte integrate del processo di sviluppo del prodotto. Il modello evolutivo si basa su due tipologie di sviluppo basate sui prototipi:
Si iniziano a sviluppare le parti del sistema che sono già ben specificate aggiungendo nuove caratteristiche secondo le necessità fornite dal cliente man mano. Consente di scrivere il software in maniera incrementale.
• Il prodotto software evolve continuamente (aggiunta di funzionalità, cambio di piattaforma, cambiamenti nell’organizzazione dell’azienda che lo utilizza e quindi adeguamento del software, ...).
Nella fase di evoluzione:
• si analizza l’esperienza di uso del software sul campo e si utilizza la maggiore
conoscenza per definire nuovi obiettivi,
• si determinano esigenze e nuove funzionalità emerse o non coperti in
precedenza,
• si riprende il ciclo dalla definizione dei requisiti alla messa in esercizio e
manutenzione del nuovo software nato dall’arricchimento ed evoluzione del
precedente.
Problemi
• Mancanza di visibilità del processo
• Sistemi spesso poco strutturati
• Possono essere richieste particolari capacità (ad
esempio in linguaggi per prototyping rapido)
Applicabilità
• Sistemi interattivi di piccola o media dimensione
• Per parti di sistemi più grandi (es. interfaccia utente)
• Per sistemi a vita breve
Lo scopo di questo tipo di prototipazione è quello di identificare meglio le specifiche richieste dall’utente sviluppando dei prototipi che sono funzionanti. Il prototipo sperimenta le parti del sistema che non sono ancora ben comprese oppure serve per valutare la fattibilità di un approccio.
Il prototipo è un mezzo attraverso il quale si interagisce con il
committente per accertarsi di aver ben compreso le sue richieste,
per specificare meglio tali richieste, per valutare la fattibilità del
prodotto.
Non appena il prototipo è stato verificato da parte del cliente o da parte degli sviluppatori può essere buttato via.
Esistono 2 tipi di prototipazione:
• mock-ups(schermate d'applicazione): produzione completa dell’interfaccia utente.
Consente di definire con completezza e senza ambiguità i
requisiti (si può, già in questa fase, definire il manuale di
utente)
• breadboards: implementazione di sottoinsiemi di
funzionalità critiche del sistema, non nel senso della fattibilità
ma in quello dei vincoli pesanti che sono posti nel
funzionamento del sistema (carichi elevati, tempo di risposta, ...),
senza le interfacce utente. Serve a capire se determinate funzionalità
possono essere implementate.
Produce feedbacks su come implementare la funzionalità (in pratica si cerca di
conoscere prima di garantire).
Basato su un modello matematico che viene trasformato da una rappresentazione formale ad un’altra. Le trasformazioni devono preservare la correttezza. Questo garantisce che il programma
soddisfi la specifica.
Lo sviluppo viene visto come una sequenza di passi che trasformano formalmente una specifica in una implemantazione.
Questo modello comporta i seguenti problemi:
nel personale in quanto non è facile trovare persone con le conoscenze giuste per poterlo implementare ;
difficoltà nella specifica formale di parti del sistema(ad esempio: l'interfaccia utente);
costi di sviluppo generalmente più elevati;
difficoltà di dialogo col cliente, in quanto questi non comprende le specifiche formali.
I campi d'applicazione che giustificano tale complessità di sviluppo sono da ricercarsi nei sistemi critici dove sicurezza ed efficienza devono essere garantite.
E’ previsto un repository dove vengono depositate le componenti sviluppate durante le fasi del ciclo di vita. Le componenti vengono prese dal repository e riutilizzate quando necessario.
Questo modello è particolarmente usato per sviluppare software in linguaggi Object Oriented.
Utilizzato per la progettazione di grandi software che richiedono tempi ristretti. Vengono rilasciate delle release funzionanti (deliverables) anche se non soddisfano pienamente i requisiti del cliente.
Vi sono due tipi di modelli incrementali:
Le fasi alte del modello a cascata vengono realizzate e portate a termine, il software viene finito, testato e rilasciato ma non soddisfa tutte le aspettative richieste dall’utente(mancano alcuni sottosistemi che implementano funzionalità meno rilevanti). Le funzionalità non incluse vengono comunque implementate e aggiunte in tempi diversi in base alla loro priorità. Con questo tipo di modello diventa fondamentale la parte di integrazione tra sottosistemi.
E’ un particolare modello a cascata in cui ad ogni fase viene applicato il modello ad implementazione incrementale e successivamente le singole fasi vengono sviluppate e integrate con il sistema esistente. Il sistema viene sviluppato seguendo le normali fasi e ad ogni fase l’output viene consegnato al cliente.
Proposto per supportare l’ analisi dei rischi è un modello di tipo ciclico, dove il raggio della spirale rappresenta il costo accumulato durante lo svolgimento del progetto.
Ogni ciclo della spirale rappresenta una fase del processo di sviluppo:
il più interno può essere lo studio di fattibilità, il successivo la definizione dei requisiti, il
successivo ancora la progettazione, etc.
Non sono definite fasi a priori e man mano che si cicla nella spirale, i costi aumentano.
Ogni ciclo della spirale passa attraverso i quadranti del piano che rappresentano i seguenti passi
logici:
I. determinazione di obiettivi, alternative e vincoli
II. valutazione di alternative, identificazione e risoluzione di rischi
ad esempio sviluppo di un prototipo per validare i requisiti
III. sviluppo e verifica del prossimo livello del prodotto.
modello evolutivo, se i rischi riguardanti l'interfaccia utente sono dominanti;
modello cascata se è l'integrabilità del sistema il rischio maggiore;
modello trasformazionale, se la sicurezza è più importante
IV. pianificazione della fase successiva
si decide se continuare con un altro ciclo della spirale
Una caratteristica importante di questo modello è il fatto che i rischi vengono presi seriamente in considerazione e che ogni fine ciclo produce una deliverables(release funzionanti alle quali mancano alcune funzionalità). In un certo senso può essere visto come un modello a cascata iterato più volte.
Costituisce un meta- modello dei processi software, cioè un modello per descrivere modelli
Non è detto che per un ciclo della spirale si adotti un solo modello di sviluppo
Può descrivere uno sviluppo incrementale, in cui ogni incremento corrisponde a un ciclo di spirale
Può descrivere il modello a cascata (quadranti I e II corrispondenti alla fase di studio di fattibilità e
alla pianificazione del progetto; quadrante III corrisponde al ciclo produttivo)
Differisce dagli altri modelli perché considera esplicitamente il fattore rischio.
Boehm suggerisce di considerare, per ciascun ciclo, le seguenti voci:
• Obiettivi
• Vincoli
• Alternative
• Rischi
• Soluzioni per i rischi
• Risultati
• Piani
• Decisioni
Rende esplicita la gestione dei rischi, focalizza l’attenzione sul riuso, determina errori in fasi iniziali, aiuta a considerare gli aspetti della qualità e integra sviluppo e manutenzione.
Richiede un aumento nei tempi di sviluppo, delle persone con capacità di identificare i rischi, una gestione maggiore del team di sviluppo e quindi anche un costo maggiore.
Compito di chi gestisce (il manager) è minimizzare i rischi
Tipologie di rischi: personale non adeguato, scheduling, budget non realistico, sviluppo del sistema sbagliato …
Il rischio è insito in tutte le attività umane ed è una misura dell’incertezza sul risultato dell’attività
Alti rischi provocano ritardi e costi imprevisti
Il rischio è collegato alla quantità e qualità delle informazioni disponibili: meno informazione si ha più alti sono i rischi
2.10.1 Rischi sui modelli
2.10.2 Visibilità dei diversi Modelli
Modello del processo |
Visibilità del processo |
Modello a cascata |
Buona visibilità, ogni attività produce delle deliverables (release funzionanti) |
Sviluppo evolutivo |
Visibilitàpovera, antieconomico a produzione |
Trasformazioni |
Buon visibilità, documenti devono essere prodotti |
Sviluppo |
Visibilitàmoderata, può essere artificioso per la |
Modelloa spirale |
Buon visibilità, ogni segmento ed ogni anello |
Il project management racchiude le attività necessarie per assicurare che un progetto software venga sviluppato rispettando le scadenze e gli standard.
Le entità fisiche che prendono parte al project management sono:
Esistono vari tipi di team di sviluppo qui di seguito indicati:
Assenza di un leader permanente (possono esistere dei leader a rotazione), consenso di gruppo, organizzazione orizzontale.
Vantaggi: individuazione degli errori,
adatto a problemi difficili.
Svantaggi: difficile da imporre,
non è scalabile.
Vi è un leader che controlla e coordina il lavoro ed assegna i problemi ai gruppi a lui sottomessi. I sottogruppi hanno un leader e sono composti da 2 a 5 persone. I leader dei sottogruppi possono comunicare tra loro come anche i membri dei sottogruppi possono comunicare in maniera orizzontale.
Vi è un leader che decide sulle soluzioni e la organizzazione dei gruppi. Ogni gruppo ha un proprio leader che assegna e controlla il lavoro dei componenti. I leader dei gruppi non comunicano tra loro ma possono comunicare solo con il loro capo. I membri dei gruppi non comunicano tra loro ma solo con il capo gruppo.
Viene definita una descrizione di massima del progetto,
gli elementi vengono consegnati con le rispettive date di consegne e vengono pianificati eventuali cambiamenti.
1.1 Overview del Progetto
Descrizione di massima del progetto e del prodotto.
1.2 Deliverables del Progetto
Tutti gli items che saranno consegnati, con data e luogo di
consegna
1.3 Evoluzione del Progetto
Piani per cambiamenti ipotizzabili e non
1.4 Materiale di riferimento
Lista dei documenti cui ci si riferisce nel Piano di Progetto
Vengono definite le relazioni tra le varie fasi del progetto, la sua struttura organizzativa, le interazioni con entità esterne, le responsabilità di progetto (le principali funzioni e chi sono i responsabili).
2.1 Modello del Processo
Relazioni tra le varie fasi del processo
2.2 Struttura Organizzativa
Gestione interna, carta dell’organizzazione
2.3 Interfacce Organizzative
Relazioni con altre entità
2.4 Responsabilità di Progetto
Principali funzioni e attività;
Di che natura sono?
Chi ne è il responsabile ?
Si definiscono gli obiettivi e le priorità, le assunzioni, le dipendenze, i vincoli, i rischi con i relativi meccanismi di monitoraggio, pianificazione dello staff.
3.1 Obiettivi e Priorità
3.2 Assunzioni, Dipendenze, Vincoli
Fattori esterni
3.3 Gestione dei rischi
Identificazione, Valutazione, Monitoraggio dei rischi
3.4 Meccanismi di monitoraggio e di controllo
Meccanismi di reporting, format, flussi di informazione,
revisioni
3.5 Pianificazione dello staff
Skill necessari (cosa?, quanto?, quando?)
Vanno specificati i sistemi di calcolo, i metodi di sviluppo, la struttura del team, il piano di documentazione del software e viene pianificata la gestione della qualità.
4.1 Metodi, Strumenti e Tecniche
Sistemi di calcolo, metodi di sviluppo, struttura del team, ecc.
Standards, linee guida, politiche.
4.2 Documentazione del Software
Piano di documentazione, che deve includere milestones, e revisioni
4.3 Funzionalità di supporto al progetto
Pianificazione della qualità
Pianificazione della gestione delle configurazioni
5.1 Work Packages
Il progetto è scomposto in tasks; definizione di ciascun task
5.2 Dipendenze
Relazioni di precedenza tra funzioni, attività e task
5.3 Risorse Necessarie
Stima delle risorse necessarie, in termini di personale, di tempo di
computazione, di hardware particolare, di supporto software ecc.
5.4 Allocazione del Budget e delle Risorse
Associa ad ogni funzione, attività o task il costo relativo
5.5 Pianificazione
Deadlines e Milestones
Il progetto viene diviso in task (attività, mansioni) e a ciascuno assegnata una priorità, le dipendenze, le risorse necessarie e i costi. Le attività devono essere organizzate in modo da produrre risultati valutabili dal management. I risultati possono essere milestone o deliverables; il primo rappresenta il punto finale di un’attività di processo, il secondo è un risultato fornito al cliente.
Ogni task è un’unità atomica definita specificando: nome e descrizione del lavoro da svolgere, precondizioni per poter avviare il lavoro, risultato atteso, rischi. I vari task vanno organizzati in modo da ottimizzare la concorrenza e minimizzare la forza lavoro. Lo scopo è quello di minimizzare la dipendenza tra le mansioni per evitare ritardi dovuti al completamento di altre attività.
Le attività del progetto vengono divise in task che sono caratterizzati dai tempi di inizio e fine, una descrizione, le precondizioni di partenza, i rischi possibili ed i risultati attesi.
Scheduling di progetto
Divide il progetto in mansioni (tasks) e stima il tempo e le risorse necessarie per completare ogni singola mansione
Organizza le mansioni in modo concorrente, per ottimizzare la forza lavoro
Minimizza la dipendenza tra i singoli task per evitare ritardi dovuti all’attesa del completamento di
un altro task
Problemi nello scheduling
E’ difficile stimare la difficoltà dei problemi ed il costo di sviluppo di una soluzione
La produttività non è proporzionale al numero di persone che lavoranno su una singola mansione
Aggiungere personale in un progetto in ritardo può aumentare ancora di più il ritardo
Rappresentazione Grafica dello scheduling del progetto:
PERT è l'acronimo di Program Evaluation and Review Technique, cioè Tecnica di valutazione e revisione di programma.
Gli eventi (fasi realizzate) sono rappresentati da cerchi o da altre forme chiuse,
le attività sono rappresentate da frecce che collegano i cerchi,
le non attività che collegano due eventi sono rappresentate da frecce tratteggiate.
I diagrammi di PERT sono utili soprattutto se mostrano il tempo previsto (Working time) per completare una certa attività sulla linea apposita
Mostra la suddivisione del lavoro in attività evidenziando le dipendenze e il cammino.
Cammino Più Lungo = Cammino Critico
ES = EARLIEST START TIME ovvero il minimo giorno di inizio dell’attività, a partire dal minimo tempo necessario per le attività che precedono. Earliest Start Time per un'attività uscente da un nodo è il più grande tra i tempi EF delle attività entranti nel nodo.
EF = EARLIEST FINISH TIME ovvero dato ES e la durata dell’attività, il minimo giorno in cui
l’attività può terminare. Se t è la durata attesa dell'attività, EF = ES + t
LF: latest finish time: il giorno massimo in cui quel job deve finire senza che si crei
ritardo per i job che dipendono da lui.
LS: latest start time: dato LF e la durata del job, il giorno massimo in cui quel job
deve iniziare senza provocare ritardo per i job che dipendono da lui.
Il management dei rischi identifica i rischi possibili e cerca di pianificare per minimizzare il loro effetto sul progetto, pianifica i rischi e li monitorizza.
I rischi da identificare sono di vari tipi tra cui: rischi tecnologici, rischi delle risorse umane, rischi organizzativi, rischi nei tools, rischi relativi ai requisiti, rischi di stima/sottostima.
Le tipologie di rischi sono le seguenti:
Alcune tecnologie di supporto (database, componenti esterne) non sono abbastanza validi come ci aspettavamo.
Non è possibile reclutare staff con la competenza richiesta oppure non è possibile fare formazione allo staff.
Cambi nella struttura organizzativa possono causare ritardi nello sviluppo del progetto.
Ad esempio il codice/documentazione prodotto con un determinato strumento non è abbastanza efficiente.
Cambiamenti nei requisiti richiedono una revisione del progetto già sviluppato.
Il tempo richiesto, la dimensione del progetto sono stati sottostimati.
Ad ogni rischio va assegnata una probabilità che esso si verifichi e vanno valutati gli effetti dello stesso che possono essere: catastrofici, seri, tollerabili, insignificanti.
Viene considerato ciascun rischio e viene sviluppata una strategia per risolverlo. Le strategie che possiamo prendere possono essere:
Ogni rischio viene regolarmente valutato e viene verificato se è diventato meno o più probabile, inoltre i suoi aspetti vanno discussi con il management per valutare meglio i provvedimenti da adottare.
Il Modello UML può essere visto gerarchicamente come un Sistema diviso in uno o più modelli a sua volta divisi in una o più Viste. Lo scopo dei modelli UML è quello di semplificare l’astrazione di un progetto software e nascondere i dettagli non necessari alla comprensione della struttura generale.
I modelli:
• rappresentano il linguaggio dei progettisti
• rappresentano il sistema da costruire o costruito
• sono un veicolo di comunicazione
• descrivono in modo “visuale” il sistema da costruire
• sono uno strumento per gestire la complessità (siamo in grado di perdere alcuni dettagli non
necessari in un particolare contesto ed astrarre ciò che ci interessa; con un modello astratto è
più chiaro capire cosa l’applicazione deve fare).
• consentono di analizzare caratteristiche particolari del sistema
Prima di visionare i vari tipi di diagrammi, UML definisce alcune convenzioni.
I nomi sottolineati delineano le istanze, mentre nomi non sottolineati denotano tipi (o classi), i diagrammi sono dei grafi, i nodi sono le entità e gli archi sono le interazioni tra di essi, gli attori rappresentano le entità esterne che interagiscono con il sistema.
DIAGRAMMI UML
VISTE STATICHE
Descrivono la struttura statica dell’applicazione
• Use Case Diagrams (per la parte di requirements; COSA l’applicazione deve fare)
• Class Diagrams (design)
• Object Diagrams (design)
• Component Diagrams (implementazione)
• Deployment Diagrams (implementazione)
VISTE DINAMICHE
Descrivono come l’applicazione può evolvere (cosa può fare e cosa no )
• Sequence Diagrams (requirements e design)
• Collaboration Diagrams (requirements e design)
• Statechart Diagrams (design ed implementazione)
• Activity Diagrams (design ed implementazione)
Fa vedere cosa l’applicazione può fare; è uno dei diagrammi più di alto livello.
Gli USE CASE:
• definiscono il comportamento del sistema (cosa deve fare e non come)
o Le funzionalità (processi) principali
o Come il sistema agisce e reagisce (sistema attori)
• descrivono
o Il sistema
o Gli attori
o Le relazioni fra sistema e attori
o ogni diagramma può avere diversi livelli di dettaglio
Definisco cosa il sistema offre (servizi per l’utente finale…)
Allegato ai casi d'uso deve esservi il Data Dictionary che contiene descrizioni sugli attori.
Questi diagrammi servono a rappresentare l’interazione del sistema con uno o più attori e descrive tutti i vari casi possibili.
Un caso d'uso consiste di:
un nome univoco,
degli attori partecipanti (almeno 1),
una o più condizioni di entrata e di uscita,
un flusso di eventi,
eventuali condizioni eccezionali ( Requisiti non funzionali, es: timeout )
Gli attori rappresentano i ruoli, non le persone fisiche!
Se un sistema deve interagire con un altro sistema, diventa anch'esso un attore e va dunque descritto all'interno del caso d'uso.
Tra le entità di un use case diagram si possono avere varie relazioni rappresentate dagli archi con la freccia rivolta verso l’entità.
Le relazioni possono essere di vario tipo:
L’arco senza descrizione e senza freccia indica che l’attore può eseguire una certa funzionalità(l'attore è in relazione con il caso d'uso).
L’arco con linea continua e con freccia indica una generalizzazione (ereditarietà) e punta verso il caso generale.
L’arco trattegiato con la descrizione <<extends>> rappresenta un caso eccezionale che può verificarsi all'interno del caso d'uso e punta verso il caso d'uso principale (estende il caso d'uso principale – è una variante di).
<<extends>> è uno stereotipo che serve ad estendere UML.
Se due casi d'uso sono in relazione fra loro esiste una dipendenza! Ad esempio I casi d'uso ProdottoNonErogabile, RestoNonDisponibile, DistributoreFuoriUso sono casi d'uso secondari e non possono esistere senza il caso d'uso principale AcquistaProdotto.
L'arco trattegiato con la descrizione <<includes>> rappresenta un comportamento comune a più casi d'uso. Serve a fare una decomposizione funzionale dei casi d'uso. Indica che una determinata funzionalità implica l’esecuzione di un altra e punta verso quella che viene eseguita per implicazione.
I casi d'uso PurchaseMultiCard e PurchaseSinglesTicket non possono essere eseguiti se non viene eseguito prima CollectMoney.
Rappresentano la struttura del sistema. Vengono usati durante la fase di analisi dei requisiti e il system design di un modello.
È possibile definire diagrammi contenenti classi astratte e altri in cui compaiono istanze delle stesse con i relativi attributi specificati. Ogni nodo del grafo rappresenta una classe o un istanza con un nome (nel caso di un’istanza il nome è sottolineato) e contiene i suoi attributi e il suoi comportamenti (le operazioni che essa svolge). Ogni attributo ha un tipo e ogni operazione ha una firma.
Una classe non segue uno schema di rappresentazione rigido. Infatti l'unica informazione necessaria richiesta è il nome dalla classe.
Una classe incapsula in essa attributi e operazioni, queste ultima rappresentano i metodi.
Le entità del grafo(classi) possono essere interconnesse tramite archi con freccia, senza freccia o tratteggiati ed avere le seguenti relazioni:
• sincroni (resto bloccato finché non ho una risposta) – linea con freccia
• asincroni (posso fare altro mentre aspetto la risposta) – linea con freccia con punta a metà
• di risposta <-------------------
• flussi di controllo --------------------
La risposta è generalmente legata ad un messaggio sincrono.
Ad ogni messaggio possiamo associare delle etichette;
ETICHETTE
Possiamo avere delle condizioni (parentesi quadre) – es: [x>0] do (manda il messaggio se x>0)
Oppure delle iterazioni – es: *do (manda * volte il messaggio)
DESCRIZIONE DEL TEMPO
Il tempo scorre dall’alto verso il basso
Per messaggi istantanei (tempo di trasmissione trascurabile)
Fanno vedere il comportamento di un attività o di un oggetto.
Rappresentano i vari stati e le transizioni che può ottraversare un oggetto in base ai messaggi che riceve.
Sono in grado di dire come un oggetto reagisce quando riceve un segnale oppure in base ad un
evento mediante azioni e transizioni.
Descrivono una sequenza di stati di un oggetto in risposta a determinati eventi. Rappresentano anche le transizioni causate da un evento esterno e l’eventuale stato in cui esso viene portato.
OPERAZIONI
Abbiamo azioni e attività.
AZIONE:
• durata istantanea
• associata a transizioni – entrata/uscita da uno stato
ATTIVITA’:
• durata prolungata
• associata agli stati
Descriviamo il comportamento attraverso un insieme di attività
Definiamo le azioni che compongono un’attività della nostra applicazione.
Gli activity diagram sono utili per descrivere:
• sequenze di azioni
• concorrenza tra azioni
• come la concorrenza è distribuita
• nel business plan, i passi per arrivare ad un goal
E’ un particolare diagramma a stati in cui però al posto degli stati vi sono delle funzioni. Gli archi rappresentano la motivazione di esecuzione della funzione a cui punta.
Sono particolari statechar diagram in cui ogni stato rappresenta una attività. Servono a modellare oggetti.
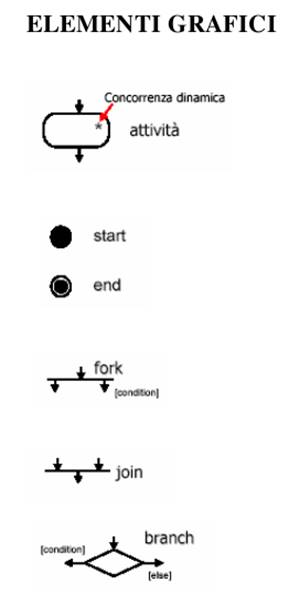
E’ possibile modellare situazioni di concorrenza in cui varie funzioni vengono eseguite simultaneamente utilizzando la seguente forma di grafico:
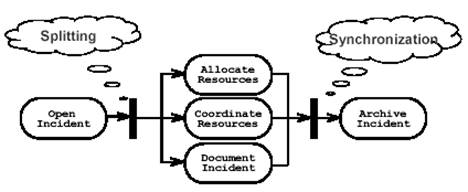
Figura 6 Diagramma delle attività con concorrenza
Si può cercare migliorare la semplicità di un sistema raggruppando elementi del modello in packages. Ad esempio è possibile raggruppare use case o attività.
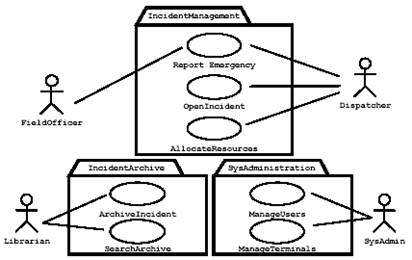
Figura 7 Raggruppamento
L’ingegneria dei requisiti coinvolge due attività: raccolta dei requisiti e analisi dei requisiti.
La raccolta dei requisiti richiede la collaborazione tra più gruppi di partecipanti, di tipologie e conoscenze diversificate. Gli errori commessi durante questa fase sono difficili da correggere e vengono spesso notati nella fase di consegna.
Alcuni errori possono essere:
funzionalità non specificate o incorrette;
interfacce poco intuitive.
Utenti e sviluppatori devono collaborare per scrivere il documento di specifica dei requisiti che è scritto in linguaggio naturale per poi essere successivamente formalizzato e strutturato (in UML o altro) durante la fase di analisi per produrre il modello di analisi.
Il primo documento (la specifica dei requisiti) è utile al fine di favorire la comunicazione con il cliente e gli utenti, il documento prodotto nell’analisi è usato dagli sviluppatori.
DISTINZIONE TRA PROBLEMA E SOLUZIONE
Prima di procedere alla soluzione bisogna capire qual' è il problema.
• I REQUISITI si occupano del problema (WHAT-Cosa)
• DESIGN ed IMPLEMENTAZIONE trattano lo spazio della soluzione (HOW-Come)
REQUISITI
I requisiti per un manufatto sono, in generale, le proprietà richieste, ed in particolare, gli effetti che
la macchina deve produrre sul dominio del problema.
Il processo di ingegnerizzazione serve a colmare il gap tra i requisiti ed i materiali grezzi
collegando tutto ciò che è disponibile (linguaggi, componenti…) ed assemblandoli in modo da
soddisfare i requisiti
LO SPAZIO DEL PROBLEMA
Occorre capire qual è il dominio applicativo.
IL PROCESSO DI REQUIREMENTS
C’è il problema di capire cosa deve fare il sistema a quali sono i vincoli al contorno.
Occorre un interazione con:
• Clienti
• Utenti
• Esperti del dominio
Occorre identificare gli stakeholders (azionisti); sono gli attori fondamentali, le persone rilevanti
per le applicazioni.
La raccolta dei requisiti e l’analisi dei requisiti si focalizzano sul punto di vista dell’utente e definiscono i confini del sistema da sviluppare, in particolare vengono specificate:
Le specifiche dei requisiti sono una sorta di contratto tra il cliente e gli sviluppatori e deve essere curata con attenzione in ogni suo dettaglio. Inoltre le parti del sistema che comportano un maggior rischio devono essere prototipate e provate con simulazioni per controllare la loro funzionalità e ed ottenere un riscontro dall’utente.
Esistono varie tipologie di requisiti qui di seguito specificati:
Descrivono le interazioni tra il sistema e l’ambiente esterno (utenti e sistemi esterni) indipendentemente dall’implementazione.
Componenti principali dei requisiti funzionali sono:
• Il dominio applicativo
• Il problema da risolvere
• La macchina da costruire (la soluzione software)
Descrivono aspetti del sistema che non sono legati direttamente alle funzionalità del sistema. Ad esempio sono requisiti non funzionali dettagli implementativi tipo timeout e altro.
Altri requisiti non funzionali sono parte dello standard FURPS e sono di qualità e di vincoli.
I requisiti devono essere continuamente validati con il cliente e l’utente, la validazione degli stessi è un aspetto molto importante perché ha lo scopo di non tralasciare nessun aspetto.
I requisiti devono rispettare le seguenti caratteristiche:
Altri requisiti possono essere specificati in base alla sorgente delle informazioni.
Il greenfield engineering avviene quando lo sviluppo di un’applicazione parte da zero, senza alcun sistema preesistente.
Il re-engineering è un tipo di raccolta dei requisiti dove c’è un sistema preesistente che deve essere riprogettato a causa di nuove esigenze o nuove tecnologie.
L’interface engineering avviene quando è necessario riprogettare un sistema per farlo lavorare in un nuovo ambiente. Un esempio possono essere i sistemi legacy che vengono lasciati inalterati nelle interfacce.
Un attore è un entità esterna che comunica con il sistema e può essere un utente, un sistema esterno o un ambiente fisico.
Ogni attore ha un nome univoco ed una breve descrizione sulle sue funzionalità (es. Teacher: una persona; Satellite GPS: fornisce le coordinate della posizione).
Un modo molto semplice per identificare gli attori di un sistema e porsi le seguenti domande:
Uno scenario è una descrizione informale, concreta e focalizzata di una singola caratteristica di un sistema e descrive cosa le persone fanno e sperimentano mentre provano ad usare i sistemi di elaborazione e le applicazioni.
Ogni scenario deve essere caratterizzato da un nome,da una lista dei partecipanti e da un flusso di eventi.
Esistono vari tipi di scenari:
L’identificazione degli scenari è una fase che avviene in stretta collaborazione con il cliente e l’utente.
Per poter formulare gli scenari bisogna porsi e porre all’utente le seguenti domande:
Un caso d’uso descrive una serie di interazioni che avvengono dopo un' inizializzazione da parte di un attore e specifica tutti i possibili scenari per una determinata funzionalità (visto in altri termini uno scenario è un’istanza di un caso d’uso).
Ogni caso d’uso contiene le seguenti informazioni:
Nel flusso di eventi del caso d’uso vengono distinti gli eventi iniziati degli attori da quelli iniziati del sistema in quanto quelli del sistema sono più a destra (con un tab) rispetto a quelli dell’attore.
Vengono dettagliati gli elementi che sono manipolati dal sistema, dettagliate le interazioni a basso livello tra l’attore e il sistema, specificati i dettagli su chi può fare cosa, aggiunte eccezioni non presenti, le funzionalità comuni tra i casi d’uso vengono rese distinte.
Esistono vari tipi di relazioni tra attori e casi d’uso (vedi anche lezione su UML):
La prima detta <<initiate>> viene usata per indicare che un attore può iniziare un caso d’uso,
la seconda <<participate>> invece indica che l’attore (che non ha iniziato il caso d’uso) può solo comunicare (es. ottenere informazioni) con lo stesso.
In questo modo è possibile specificare già in questa fase dettagli sul controllo di accesso in quando vengono indicate le procedure e i passi per accedere a determinate funzioni del sistema.
Durante la fase di raccolta dei requisiti utenti e sviluppatori devono creare un glossario di termini usati nei casi d’uso. Si parte dalla terminologia che gli utenti hanno (quella del dominio dell’applicazione) e successivamente si negoziano cambiamenti. Il glossario creato è lo stesso che viene incluso nel manuale utente finale.
I termini possono rappresentare oggetti, procedure, sorgenti di dati, attori e casi d’uso. Ogni termine ha una piccola descrizione e deve avere un nome univoco e non ambiguo.
Uno dei metodi per negoziare le specifiche con il cliente è il Joint Application Design (JAD) , sviluppato da IBM, che si compone di cinque attività:
Un altro aspetto importante è la tracciabilità del sistema che include la conoscenza della sorgente della richiesta e gli aspetti del sistema e del progetto. Lo scopo della tracciabilità è quello di avere una visione chiara del progetto e rendere meno complessa e lunga un’eventuale fase di modifica ad un aspetto del sistema. A tale supporto è possibile creare dei collegamenti tra i documenti per meglio identificare le dipendenze tra le componenti del sistema.
Il documento dell’analisi dei requisiti (RAD) contiene la raccolta dei requisiti e l’analisi dei requisiti ed è il documento finale del progetto, serve come base contrattuale tra il cliente e gli sviluppatori .
ESEMPIO: MONITORAGGIO DEI PAZIENTI
I pazienti in un padiglione di cura intensiva, sono monitorati da strumenti elettronici collegati ai
loro corpi mediante sensori di vario tipo.
I sensori degli strumenti misurano i fattori vitali dei pazienti: le pulsazioni, la pressione, e così via.
E’ necessario un programma che legga i valori alla frequenza specificata per ogni paziente e
memorizzi i dati su un database.
I fattori letti devono essere comparati con dei livelli di sicurezza specificati per ciascun paziente, e
le letture che superano tali valori devono essere segnalate mediante messaggi di allarme che
vengono mostrati sullo schermo nella stanza degli infermieri.
Un messaggio di allarme viene anche mostrato se uno qualsiasi dei dispositivi analogici si guasta.
CONTEXT DIAGRAM
In prima analisi il software interagisce con il centro di cura intensiva
Non da molte informazioni
DOMINI DI INTERESSE
Raffiniamo il diagramma. I domini di interesse si evincono analizzando il testo. Ci sono delle frasi
che coinvolgono degli attori:
• pazienti in un padiglione di cura intensiva, sono monitorati
• messaggi di allarme che vengono mostrati sullo schermo nella stanza degli infermieri
• allarme viene anche mostrato se uno qualsiasi dei dispositivi analogici si guasta
Da cui comprendiamo i domini di interesse
• I pazienti
• La stanza degli infermieri
• I dispositivi analogici
perché i requisiti degli utenti sono espressi in termini di dispositivi
PRINCIPIO
Il principio della rilevanza del dominio dice che: tutto quello che è rilevante per i requisiti
deve comparire da qualche parte del dominio applicativo.
DOMINI
• Cosa sono le entità del dominio?
• Che tipo di attributi/proprietà hanno?
• Che tipo di relazioni esistono tra le entità?
• Che tipo di eventi possono accadere?
CONTEXT DIAGRAM DETTAGLIATO
CONTEXT DIAGRAM: CONTENIMENTO
Per domini applicativi che non sono disgiunti (ad esempio per fenomeni condivisi)
Il dominio di connessione lo rappresentiamo come un dominio a se. indica il fatto che il dominio
è contenuto sia nel dominio applicativo (aeroplano) che nella macchina (controllore)
I fenomeni osservabili soddisfano alcune leggi che dipendono dal dominio.
Ad esempio:
ruote_girano ⇔ ci_si_muove_in_pista
ruote_si_muovono ⇔ ruote_girano
REQUISITI FUNZIONALI
Dopo aver identificato i domini (con il diagramma di contesto), occorre derivare i requisiti
funzionali che devono definire le proprietà della macchina mediante predicati che possono
coinvolgere sia fenomeni condivisi che non. In pratica:
• Il problema da risolvere va descritto in termini di dominio
• Bisognerà specificare le proprietà che saranno realizzate dal software
• Possono essere formalizzati come predicati su fenomeni osservabili nel dominio applicativo
• I predicati possono coinvolgere sia fenomeni condivisi che non
REQUISITI VS SPECIFICA
Specifica -> Rappresenta i vincoli sui fenomeni condivisi tra macchina ed ambiente, come
deve comportarsi la macchina. Devono essere soddisfatti dal software. Non
dicono come la macchina dovrà ottenere certi risultati, ma ciò che deve essere
fatto in termini di segnali gestibili dalla macchina
Requisiti -> Proprietà che vogliamo ottenere nel mondo applicativo
Dai requisiti bisogna derivare la specifica.
SPECIFICA DEI REQUISITI
Sono un particolare tipo di requisito che trattano soltanto i fenomeni condivisi
I fenomeni vincolati dalla specifica sono quelli sotto il controllo della macchina da costruire
Esempio
la direzione di marcia può essere invertita ⇔ le ruote sono in movimento
(impedisce di andare in retromarcia se l’aereo è in volo).
L’ATTIVITA DI SPECIFICA DEI REQUISITI
Si compone di tre parti
G -> E’ il problema da risolvere, le proprietà che voglio ottenere attraverso il software (requisiti)
S -> Specifica, descrive l’interfaccia tra dominio applicativo e macchina
D -> Dominio applicativo (insieme dei fenomeni che ho nel mondo reale e proprietà)
D ∩S ⇒ G
La congiunzione delle proprietà del dominio con le specifiche devono implicare i requisiti
TERMINOLOGIA
Non è stata stabilita ed accettata una terminologia, requisiti, specifica e design sono termini usati
con significati diversi, spesso perché usati in momenti diversi dello sviluppo.
TERMINOLOGIA COMUNE
• REQUISITO per un “servizio” fornito da X espresso da Y, il quale richiede X
Proprietà che esprime l’aspettativa di Y sull’abilità di X
• SPECIFICA: contratto tra X che fornisce il servizio ed Y che ne usufruisce
• PROGETTO : la struttura che fornisce il servizio
NEL CONTESTO SPECIFICO
• REQUISITO: gli effetti richiesti da un’applicazione sull’ambiente esterno
• SPECIFICA: vincoli sull’interfaccia tra l’ambiente e la macchina
• REQUIREMENTS ENGINEERING: come progettare requisiti e specifiche
L’analisi dei requisiti è finalizzata a produrre un modello del sistema chiamato modello dell’analisi che deve essere corretto, completo, consistente e non ambiguo.
La differenza tra la raccolta dei requisiti e l’analisi è nel fatto che gli sviluppatori si occupano di strutturare e formalizzare i requisiti dati dall’utente e trovare gli errori commessi nella fase precedente (raccolta dei requisiti).
L’analisi, rendendo i requisiti più formali, obbliga gli sviluppatori a identificare e risolvere caratteristiche difficili del sistema già in questa fase, il che non avviene di solito.
Il modello dell’analisi è composto da tre modelli individuali:
Il modello ad oggetti è una parte del modello dell’analisi e si focalizza sui concetti del sistema visti individualmente, le loro proprietà e le loro relazioni. Viene rappresentato con un diagramma a classi di UML includendo operazioni, attributi e classi.
Il modello dinamico si focalizza sul comportamento del sistema utilizzando sequence diagram e diagrammi a stati. I sequence diagram rappresentano l’interazioni di un insieme di oggetti nell’ambito di un singolo caso d’uso. I diagrammi a stati rappresentano il comportamento di un singolo oggetto. Lo scopo del modello dinamico è quello di assegnare le responsabilità ad ogni singola classe, identificare nuove classi, nuove associazioni e nuovi attributi.
Nel modello ad oggetti dell’analisi e nel modello dinamico le classi che vengono descritte non sono quelle che in realtà poi verranno implementate nel software ma rappresentano ancora un punto di vista dell’utente. Spesso infatti ogni classe del modello viene mappata con una o più classi del codice sorgente, e gli attributi e tutte le sue caratteristiche sono specificate in modo minimale.
Il modello ad oggetti è costituto da oggetti di tipo entity, boundary e control.
Gli oggetti entity rappresentano informazioni persistenti tracciate dal sistema;
gli oggetti boundary rappresentano l’interazione tra attore e sistema;
gli oggetti di controllo realizzano i casi d’uso.
Gli stereotipi entity, control e boundary possono essere inclusi nei diagrammi e attaccati agli oggetti con le notazioni <<entity>> <<control>> <<boundary>>.
Le attività che andremo a descrivere sono le seguenti:
Per identificare gli oggetti partecipanti al modello dell’analisi bisogna prendere in considerazione quelli identificati durante la specifica di requisiti.
Visto che il documento della specifica dei requisiti è scritto in linguaggio naturale, è frequente riscontrare imprecisioni nel testo, oppure dei sinonimi sulla notazioni che possono indurre gli sviluppatori a considerare male gli oggetti.
Gli sviluppatori possono limitare gli errori usando delle euristiche come quella di Abbott che detta le seguenti regole:
Testo |
Modello ad oggetti |
Nomi propri |
Istanze |
Nomi comuni |
Classi |
Verbi di fare |
Operazioni |
Verbi essere |
Ereditarietà |
Verbi avere |
Aggregazioni |
Verbi modali (es. deve essere) |
Costanti |
Aggettivi |
Attributi |
Oltre a quella di Abbott è possibile usare questa ulteriore euristica che suggerisce di dare peso alle seguenti caratteristiche dell’analisi dei requisiti:
Gli oggetti boundary rappresentano l’interfaccia del sistema con l’attore. Ogni attore dovrebbe interagire con almeno un oggetto boundary.
Gli oggetti boundary raccolgono informazioni dall’attore e le traducono in un formato che può essere usato dagli oggetti entity e control.
Essi non descrivono in dettaglio gli aspetti visuali dell’interfaccia utente: ad esempio specificare scroll-bar o menu-item può essere troppo dettagliato.
Per scovare gli oggetti boundary è possibile anche in questo caso usare un’euristica:
Gli oggetti Control sono responsabili del coordinamento tra gli oggetti entity e boundary e lo scopo è quello di prendere informazioni dagli oggetti boundary e inviarli agli oggetti entità. Un oggetto control viene creato all’inizio di un caso d’uso e termina alla fine di questo. Anche questo come gli oggetti entità e boundary si basa su delle euristiche:
Mappare i casi d’uso in sequence diagram serve per mostrare il comportamento tra gli oggetti partecipanti e ne mostrano l’interazione.
I sequence diagram non sono comprensibili all’utente ma sono uno strumento più preciso di supporto agli sviluppatori.
In un sequence diagram:
Mediante i sequence diagram è possibile trovare comportamenti o oggetti mancanti. Nel caso manchi qualche entità è necessario ritornare ai casi d’uso, ridefinire le parti mancanti e tornare a questa fase per ricreare il sequence diagram.
Un’associazione è una relazione tra due o più oggetti/classi. Ogni associazione ha un nome, un ruolo ad ogni capo dell’arco che identifica la funzione di ogni classe rispetto all’associazione e una molteplicità che indica ad ogni capo il numero di istanze possibili (vedi UML per dettagli).
Un’utile euristica per trovare le associazione è la seguente:
Identifica che un oggetto è parte di un altro oggetto o lo contiene (vedi UML per dettagli).
Gli attributi sono proprietà individuali degli oggetti/classi. Ogni attributo ha un nome, una breve descrizione e un tipo che ne descrive i possibili valori.
L’euristica di Abbott indica che gli attributi possono essere identificati nel linguaggio naturale del documento delle specifiche prendendo in considerazione gli aggettivi.
Gli oggetti che hanno un ciclo di vita più lungo dovrebbero essere descritti in base agli stati che essi possono assumere. Per fare ciò vengono usati i diagrammi a stati.
Una volta che il modello dell’analisi non subisce più modifiche o ne subisce raramente è possibile passare alla fase si revisione del modello. La revisione del modello deve essere fatta prima dagli sviluppatori e poi insieme dagli sviluppatori e gli utenti.
L’obiettivo di questa attività di revisione è stabilire che la specifica risulta essere: corretta, completa, consistente e chiara,
Domande da porsi per assicurarsi della correttezza:
Domande da porsi per assicurarsi della completezza:
Domande da porsi per assicurarsi della consistenza:
Domande da porsi per assicurarsi della chiarezza:
Gli scopi del system design sono quelli di definire gli obiettivi di progettazione del sistema, decomporre il sistema in sottosistemi più piccoli in modo da poterli assegnare a team individuali e selezionare alcune strategie quali:
Il system design si focalizza sul dominio di implementazione, prende in input il modello di analisi e dopo averlo trasformato, da in output un modello del sistema che include la decomposizione del sistema in sottosistemi e la descrizione delle strategie dette sopra.
Le attività del system design globalmente possono essere divise in tre fasi:
In questa fase gli sviluppatori definiscono le priorità delle qualità del sistema. Molti obiettivi possono essere ricavati utilizzando requisiti non funzionali o dal dominio dell’applicazione, altri vengono forniti direttamente dal cliente. Per ottenere gli obiettivi finali vanno seguiti dei criteri di progettazione tenendo presente performance, affidabilità, costi, mantenimento e utente finale.
In questi criteri vengono inclusi: tempo di risposta, throughput (quantità di task eseguibili in un determinato periodo di tempo) e memoria.
L’affidabilità include criteri di
robustezza (capacità di gestire condizioni non previste),
attendibilità (non ci deve essere differenza tra il comportamento atteso e quello osservato), disponibilità (tempo in cui il sistema è disponibile per l’utilizzo),
tolleranza ai fault (capacità di operare in condizioni di errore),
sicurezza,
fidatezza (capacità di non danneggiare vite umane).
Vanno valutati i costi di sviluppo del sistema, alla sua installazione e al training degli utenti, eventuali costi per convertire i dati del sistema precedente, costi di manutenzione e costi di amministrazione.
Tra i criteri di mantenimento troviamo:
estendibilità,
modificabilità,
adattabilità,
portabilità,
leggibilità e tracciabilità dei requisiti.
In criteri dell’utente finale da tenere in considerazione sono quelli di utilità (quanto bene il sistema dovrà facilitare e supportare il lavoro dell’utente) e quelli di usabilità.
Spesso quando si progetta un sistema non è possibile rispettare tutti i criteri di qualità contemporaneamente, viene quindi utilizzata una strategia di trade-off (compromesso), dunque viene data una priorità maggiore ad alcuni criteri tenendo presente scelte manageriali quali scheduling e budget.
Utilizzando come base i casi d’uso e l’analisi e seguendo una particolare architettura software (MVC, Client-Server, ecc.) il sistema viene decomposto in sottosistemi.
Lo scopo è quello di poter assegnare a un singolo sviluppatore o ad un team parti software semplici.
In questa fase viene descritto come i sottosistemi sono collegati alle classi.
Un sottosistema è caratterizzato dai servizi (insieme di operazioni) che esso offre agli altri sottosistemi. L’insieme di servizi che un sistema espone viene chiamato interfaccia (API: application programming interface) che include, per ogni operazione: i parametri, il tipo e i valori di ritorno. Le operazioni che essi svolgono vengono descritte ad alto livello senza entrare troppo nello specifico.
Il sistema va diviso in sottosistemi tenendo presente queste due proprietà:
Accoppiamento (coupling) ;
Coesione (cohesion).
Misura quanto un sistema è dipendente da un altro.
Due sistemi si dicono loosely coupled (leggermente accoppiati) se una modifica in un sottosistema avrà poco impatto nell’altro sistema, mentre si dicono strongly coupled (fortemente accoppiati) se una modifica su uno dei sottosistemi avrà un forte impatto sull’altro.
La condizione ideale di accoppiamento è quella di tipo loosely in quanto richiede meno sforzo quando devono essere modificate delle componenti.
Se ad esempio, tre componenti usano lo stesso servizio esposto da una componente che potrebbe essere modificata spesso, conviene frapporre tra di essere una nuova componente che ci permette di evitare una modifica alle tre componenti che usufruiscono del servizio.
Ovviamente ove non sono presenti componenti che si pensa debbano essere modificate spesso, non conviene utilizzare questa strategia in quanto aggiungerebbe complessità di sviluppo e di calcolo al sistema.
Misura la dipendenza tra le classi contenute in un sottosistema.
La coesione è alta se due componenti di un sottosistema realizzano compiti simili o sono collegate l’una con l’altra attraverso associazioni (es. ereditarietà), è invece bassa nel caso contrario.
L’ideale sarebbe quello di avere sottosistemi con coesione interna alta.
La decomposizione del sistema avviene utilizzando layer e/o partizioni.
Con la decomposizione in layer il sistema viene visto come una gerarchia di sottosistemi. La gerarchia riduce la complessità.
Un layer è un raggruppamento di sottosistemi che forniscono servizi correlati. I layer per implementare un servizio potrebbero usare a sua volta servizi offerti dai layer sottostanti ma non possono usare servizi dei livelli più alti.
Con i layer si possono avere due tipi di architettura: chiusa e aperta.
Con l’architettura chiusa un layer può accedere solo alle funzionalità del layer immediatamente a lui sottostante, con quella aperta il layer può accedere alle funzionalità del layer sottostante e di tutti gli altri sotto di esso.
Nel primo caso si ottiene un alta manutentibilità e portabilità,
nel secondo una maggiore efficienza in quanto si risparmia l’overhead delle chiamate in cascata.
Se un sottosistema è un layer, spesso è chiamato macchina virtuale.
Il sistema viene diviso in sottosistemi paritari (peer) fra loro, ognuno dei quali è responsabile di diverse classi di servizi.
In generale una decomposizione di un sistema avviene utilizzando ambedue le tecniche. Infatti il sistema viene prima diviso in sottosistemi tramite le partizioni e successivamente ogni partizione viene organizzata in layer finché i sottosistemi non sono abbastanza semplici da essere sviluppati da un singolo sviluppatore o team.
Un architettura software include scelte relative alla decomposizione in sottosistemi, flusso di controllo globale, gestione delle condizione limite e i protocolli di comunicazione tra i sottosistemi.
E’ da notare che la decomposizione dei sottosistemi è una fase molto critica in quando una volta iniziato lo sviluppo con una determinata decomposizione è complesso ed oneroso dover tornare indietro in quanto molte interfacce dei sottosistemi dovrebbero essere modificate.
Alcuni stili architetturali che potrebbero essere usati sono:
Con questo stile tutti i sottosistemi accedono e modificano i dati tramite un oggetto repository. Il flusso di controllo viene dettato dal repository tramite un cambiamento dei dati oppure dai sottosistemi tramite meccanismi di sincronizzazione o lock.
I vantaggi di questo stile si vedono quando si implementano applicazioni in cui i dati cambiano di frequente poiché si evitano incoerenze.
Considerando i problemi che questo stile può dare sicuramente si può notare che il repository può facilmente diventare un collo di bottiglia in termini di prestazioni e inoltre il coupling(accoppiamento) tra i sottosistemi e il repository e altissimo: una modifica all’API del repository comporta la modifica di tutti sottosistemi che lo utilizzano.
È un caso particolare dell'architettura Repository.
Il sistema viene diviso in tre sottosistemi: Model, View e Control.
Il sottosistema Model implementa la struttura dati centrale,
il Control o controller gestisce il flusso di controllo (cioè, si occupa di prendere l’input dall’utente e di inviarlo al Model),
il View è la parte di interazione con l’utente.
Uno dei vantaggi di MVC si vede quando le interfacce utente (View) vengono modificate più di frequente rispetto alla conoscenza del dominio dell’applicazione (Model). Per questo motivo MVC è l’ideale per sistemi interattivi e quando il sistema deve avere viste multiple.
Il sottosistema server fornisce servizi ad una serie di istanze di altri sottosistemi detti client i quali si occupano dell’interazione con l’utente. La maggior parte della computazione viene svolta a lato server. Questo stile è spesso usato in sistemi basati su database in quanto è più facile gestire l’integrità e la consistenza dei dati .
E’ una generalizzazione dello stile client-server in cui però client e server possono essere scambiati di ruolo ed ognuno dei due può fornire servizi.
I sottosistemi vengono organizzati in tre livelli hardware: interface, application e storage.
Il primo conterrà tutti gli oggetti boundary di interazione con l’utente,
il secondo include gli oggetti relativi al controllo e alle entità,
il terzo effettua l’interrogazione e la ricerca di dati persistenti.
Quando si decidono le componenti di un sottosistema bisognerebbe tenere presente che la maggior parte dell’interazione tra le componenti dovrebbe avvenire all’interno di un sottosistema allo scopo di ottenere un’alta coesione.
Le euristiche per scegliere le componenti dei sottosistemi sono le seguenti:
Le attività del system design sono le seguenti:
Molti sistemi complessi necessitano di lavorare su più di un computer interconnessi da rete. L’uso di più computer può ottimizzare le performance e permettere l’utilizzo del sistema a più utenti distribuiti sulla rete.
In questa fase vanno prese alcune decisioni per quanto riguarda le piattaforme hardware e software su cui il sistema dovrà girare (es Unix vs Windows, Intel vs Sparc etc).
Una volta decise le piattaforme è necessario mappare le componenti su di esse. Questa operazione potrebbe portare all’introduzione di nuove componenti per interfacciare i sottosistemi su diverse piattaforme (es. una libreria per il collegamento ad un DBMS).
Sfortunatamente, da una parte, l’introduzione di nuovi nodi hardware distribuisce la computazione, dall’altro introduce alcune problematiche tra cui la sincronizzazione, la memorizzazione, il trasferimento e la replicazione di informazioni tra sottosistemi.
Il modo in cui i dati vengono memorizzati può influenzare l’architettura del sistema (vedi lo stile architetturale repository) e la scelta di uno specifico database . In questa fase vanno identificati gli oggetti persistenti e scelto il tipo di infrastruttura da usare per memorizzarli (dbms, file o altro).
Gli oggetti entity identificati durante l’analisi dei requisiti sono dei buoni candidati a diventare persistenti. Non è detto però che tutti gli oggetti entità debbano diventare persistenti. In generale i dati sono persistenti se sopravvivono ad una singola esecuzione del sistema. Il sistema dovrà memorizzare i dati persistenti quando questi non servono più e ricaricarli quando necessario.
Una volta decisi gli oggetti dobbiamo decidere come questi oggetti devono essere memorizzati. Principalmente potremmo avere a disposizione tre mezzi: file, dbms relazionale e dbms ad oggetti.
La prima tipologia da una parte richiede una logica più complessa per la scrittura e lettura, dall’altra permette un accesso ai dati più efficiente.
Un DMBS relazione fornisce un’ interfaccia di più alto livello rispetto al file. I dati vengono memorizzati in tabelle ed è possibile utilizzare un linguaggio standard per le operazioni (SQL). Gli oggetti devono essere mappati sulle tabelle per poter essere memorizzati.
Un database orientato ad oggetti è simile ad un DBMS relazionale con la differenza che non è necessario mappare gli oggetti in tabelle in quanto questi vengono memorizzati così come sono. Questo tipo di database riduce il tempo di setup iniziale (si risparmia sulle decisioni di mapping) ma sono più lenti e le query sono di più difficile comprensione.
La scelta tra una tecnologia o un’altra per la memorizzazione può essere influenzata da vari fattori. In particolare conviene usare un file in questi casi:
Conviene invece usare un DBMS (relazionale e ad oggetti) in casi di:
In un sistema multi utenza è necessario fornire delle politiche di accesso alle informazioni. Nell’analisi sono stati associati casi d’uso ad attori, in questa fase vanno definite in modo più preciso le operazioni e le informazioni effettuabili da ogni singolo attore e come questi si autenticano al sistema. E’ possibile rappresentare queste politiche tramite una matrice in tre modi:
Ogni riga della matrice contiene una tripla (attore, classe, operazione). Se la tupla è presente per una determinata classe e operazioni l’accesso è consentito altrimenti no.
Ogni classe ha una lista che contiene una tupla (attore, operazione) che specifica se l’attore può accedere a quella determinata operazione della classe a cui la ACL appartiene.
Una capability è associata ad un attore ed ogni riga della matrice contiene una tupla (classe, operazione che l’attore a cui è associata può eseguire.
Scegliere una o l’altra soluzione impatta sulle performance del sistema. Ad esempio scegliere una tabella di accesso globale potrebbe far consumare molta memoria. Le altre vanno usate in base al tipo di controllo che vogliamo effettuare: se vogliamo rispondere più velocemente alla domanda “chi può accedere a questa classe?” useremo una ACL, se invece vogliamo rispondere più velocemente alla domanda “a quale operazione può eccedere questo attore?” useremo una capability.
Un flusso di controllo è una sequenza di azioni di un sistema. In un sistema Object Oriented una sequenza di azioni include prendere decisioni su quali operazioni eseguire ed in che ordine. Queste decisioni sono basate su eventi esterni generati da attori o causati dal trascorrere del tempo.
Esistono tre tipi di controlli di flusso:
Le operazioni rimangono in attesa di un input dell’utente ogni volta che hanno bisogno di elaborare dati. Questo tipo di controllo di flusso è particolarmente usato in sistemi legacy di tipo procedurale.
In questo controllo di flusso un ciclo principale aspetta il verificarsi di un evento esterno. Non appena l’evento diventa disponibile la richiesta viene direzionata all’opportuno oggetto. Questo tipo di controllo ha il vantaggio di centralizzare tutti gli input in un ciclo principale ma ha lo svantaggio di rendere complessa l’implementazione di sequenze di operazioni composte di più passi.
Questo controllo di flusso è una modifica del procedure-driven control che aggiunge la gestione della concorrenza. Il sistema può creare un arbitrario numero di threads (processi leggeri), ognuno assegnato ad un determinato evento.
Se si sceglie di usare un control-flow di tipo threads bisogna stare attenti a gestire situazioni di concorrenza in quando più thread possono accedere contemporaneamente alle stesse risorse e creare situazioni non previste.
Le condizioni limite del sistema includono lo startup, lo shutdown, l’inizializzazione e le gestione di fallimenti come corruzione di dati, caduta di connessione e caduta di componenti.
A tale scopo vanno elaborati dei casi d’uso che specificano la sequenza di operazioni in ciascuno dei casi sopra elencati.
In generale per ogni oggetto persistente, si esamina in quale caso d’uso viene creato e distrutto. Se l’oggetto non viene creato o distrutto in nessun caso d’uso deve essere aggiunto un caso d’uso invocato dall’amministratore.
Per ogni componente vanno aggiunti tre casi d’uso per l’avvio, lo shutdown e per la configurazione.
Per ogni tipologia di fallimento delle componenti bisogna specificare come il sistema si accorge di tale situazione, come reagisce e quali sono le conseguenze.
Un’eccezione è un evento o errore che si verifica durante l’esecuzione del sistema. Una situazione del genere può verificarsi in tre casi:
Nel caso in cui un errore dipenda da un input errato dell’utente, tale situazione deve essere comunicata all’utente tramite un messaggio così che lo stesso possa correggere l’input e riprovare.
Nel caso di caduta di un collegamento il sistema dovrebbe salvare lo stato del sistema in modo da poter riprendere l’esecuzione non appena il collegamento ritorna.
Un progetto di sistema deve raggiungere degli obbiettivi e bisogna assicurarsi che rispetti i seguenti criteri:
Il system design è corretto se il modello di analisi può essere mappato su di esso.
La progettazione di un sistema è completa se ogni requisito e ogni caratteristica è stata portata a compimento.
Il system design è consistente se non contiene contraddizioni.
Un progetto è realistico se il sistema può essere realizzato ed è possibile rispettare problemi di concorrenza e tecnologie.
Un system design è leggibile se anche sviluppatori non coinvolti nella progettazione possono comprendere il modello realizzato.
La gestione del system design coinvolge le seguenti attività:
La documentazione del system design può essere fatta seguendo questo template:
1. Introduction |
La suddivisione in sottosistemi effettuata nel system design influenza le decisioni sulla quantità di personale necessario per portare a termine il progetto e su come dividere i team di sviluppo.
Un team particolare, l’architecture team si occupa di suddividere il sistema in sottosistemi e di assegnare le responsabilità ai singoli team o ai singoli sviluppatori.
Un’altra figura importante è quella dell’architetto che deve assicurare la consistenza delle decisioni e dello stile delle interfacce.
La stesura del system design è effettuata in modo iterativo. Infatti alla fine di ogni stesura è possibile effettuare delle modifiche al modello relativamente a:
Le fasi dell’object design sono le seguenti:
Include l’uso di componenti off-the-shelf (riutilizzate), l’applicazione di design pattern specifici per risolvere problematiche comuni e la creazione di relazioni di ereditarietà.
I servizi dei sottosistemi identificati nel system design vengono dettagliati in termini di interfacce di classe, includendo operazioni, argomenti, firme di metodi ed eccezioni. Vengono anche aggiunte eventuali operazioni o oggetti necessari a trasferire i dati tra i sottosistemi.
La ristrutturazione manipola il modello del sistema per incrementare il riuso di codice, trasforma associazioni N-arie in binarie e associazioni binarie in semplici riferimenti, trasforma classi semplici in attributi di tipo predefinito ecc.
L’ottimizzazione ha lo scopo di migliorare le performance del sistema, aumentando la velocità, riducendo l’uso di memoria e diminuendo la molteplicità delle associazioni.
Gli oggetti possono essere divisi in due tipologie:
Rappresentano concetti del dominio dell’applicazione che sono rilevanti nel sistema (la maggior parte degli oggetti entity sono di questo tipo)
Sono oggetti che non sono mappabili su concetti relativi al dominio dell’applicazione e servono a rendere funzionale il sistema. Un esempio di oggetti di questo tipo, identificati durante l’analisi, sono gli oggetti boundary e control.
L’ereditarietà usata al solo scopo di riusare codice è detta di implementazione. Con questo tipo di ereditarietà gli sviluppatori possono riusare codice in modo veloce estendendo una classe esistente e rifinendo il suo comportamento. Un esempio di questo tipo di ereditarietà può essere la definizione di una collezione come un insieme ereditando da una tabella hash.
L’ereditarietà di specifica crea una gerarchia di concetti mappabili in una vera gerarchia (es. un insieme è una collezione ma un insieme non è una tabella hash).
La delegazione è un alternativa all’ereditarietà di implementazione applicabile quando si vuole riusare codice. Nell’esempio precedente in cui un insieme eredita da una tabella hash, è possibile usare la delegazione eliminando la relazione di ereditarietà e includendo nella classe insieme un’istanza dell’oggetto tabella hash.
In generale ogni qual volta ci troviamo di fronte ad ereditarietà di implementazione è meglio usare la delegazione. L’uso della delegazione porta alla scrittura di codice più robusto e non interferisce con le componenti già esistenti.
Il principio di Liskov asserisce che se un oggetto di tipo S può sostituire un oggetto di tipo T in qualunque posto in cui ci si aspetta di trovate T, allora S può essere definito un sottotipo di T.
In altre parole l’oggetto di tipo S è sottotipo di T se esso non sovrascrive metodi di T cambiandone il comportamento atteso.
In generale non è sempre chiaro e facile da interpretare quando conviene usare la delegazione o l’ereditarietà. I design pattern sono dei template di soluzioni a problemi comuni, raffinate nel tempo dagli sviluppatori.
Un design pattern ha quattro elementi: un nome, una descrizione del problema che risolve, una soluzione e delle conseguenze a cui porta.
Anticipare i cambiamenti del sistema è una caratteristica molto importante della progettazione. Spesso i cambiamenti tendono ad essere gli stessi per più tipologie di sistemi. Alcuni cambiamenti possibili includono:
Spesso le componenti usate per costruire il sistema vengono sostituite da altre di diversi venditori o da componenti che rispecchiano il cambiamenti del trend del mercato.
Quando i sistemi vengono integrati è possibile che ci si renda conto che il sistema è non è abbastanza performante.
La poca usabilità del software rende necessario riprogettare l’intera interfaccia grafica.
Nel dominio di applicazione è necessario aggiungere alcune caratteristiche che rendono il sistema più complesso (es. passare da un sistema a singolo utente ad un sistema multi utente).
Molti errori vengono trovati solo quando gli utenti iniziano ad usare il prodotto software.
I design pattern attraverso l’uso di delegazione, ereditarietà e classi astratte, possono aiutare ad anticipare questo tipo di cambiamenti.
Ogni design pattern che andremo ad esporre risolve uno dei problemi prima esposti.
Quando si usa uno sviluppo di tipo incrementale con testing e integrazione di sottosistemi creati da diversi sviluppatori, spesso si hanno dei ritardi nell’integrazione dei sottosistemi. Un problema simile si ha quando si vogliono avere diverse implementazioni dello stesso sottosistema (ad esempio una ottimizza la memoria e l'altra la complessità).
Per evitare ciò è possibile usare il bridge pattern che fa uso di un interfaccia comune (Implementor) ereditata da tutti i sottosistemi che implementano la stessa funzionalità (ConcreteImplementorA e ConcreteImplementorB).
Gli oggetti ConcreteImplementorX vengono creati e inizializzati dalla classe Abstraction che ne mantiene il riferimento.
In java questo può essere fatto creando un interfaccia (es Memorizzazione) che viene implementata da diverse classi (es MemorizzazioneSuFile e MemorizzazioneSuDBMS).
Il pattern adapter viene usato quando è necessario inglobare componenti esistenti nel sistema. Questo tipo di soluzione viene adottata spesso nei sistemi interattivi, dove si usano finestre, dialog e bottoni. Tipicamente quando si riusano componenti legacy o off-the-shelf gli sviluppatori devono lavorare con codice che non possono modificare e che solitamente non è stato progettato per il loro sistema.
Il pattern adapter converte l’interfaccia esistente di un sistema nell’interfaccia che gli sviluppatori si aspettano di trovare. Una classe Adapter fa da connettore tra la classe che userà l’applicazione (ClientInterface) e la classe legacy.
Consideriamo una situazione in cui ci sono delle scelte (strategie) da effettuare in base ad una situazione corrente (es il livello di traffico su una rete). Questo pattern fornisce l’abilità di funzionamento al sistema anche in situazioni che modificano a runtime (dovute a cambiamenti dell’ambiente).
Il pattern coinvolge una classe Policy che si occupa di identificare i cambiamenti nell’ambiente, una classe Stategy che si occupa di fornire un interfaccia generica verso le attuali e future implementazioni del servizio e una classe Context che viene opportunamente configurata dal Policy. In questo pattern la classe Policy seleziona la strategia concreta da utilizzare e la configura sul Context, scegliendola in base alla situazione attuale.
A prima vista potrebbe sembrare simile al bridge pattern ma in questo caso l’ambiente esterno cambia a runtime (a differenza del bridge in cui la scelta viene fatta al momento dell’inizializzazione) e quindi il Policy seleziona la strategia da seguire settando lo strategy sul Context il quale si occuperà di chiudere la strategia vecchia ed attuare la nuova.
In una situazione in cui un unico sistema deve interagire con delle componenti esterne sviluppate da diversi produttori (es: condizionatore Daikin e condizionatore Samsung) non è facile ottenere l’interoperabilità delle componenti con il sistema in quanto ogni componente/produttore offrono le stesse funzionalità (es: regolazione temperatura o spegnimento) ma con delle interfacce differenti.
In una situazione simile è possibile usare l’abstract factory pattern in cui sono presenti più factory (una per ogni casa produttrice), una classe astratta per ogni tipo di prodotto (es AbstractConditioner) e una implementazione di tale classe per ogni prodotto concreto (es DaikinConditioner e SamsungConditioner).
Tutte le factory presenti in realtà implementano una interfaccia comune AbstractFactory che permette loro un comportamento standard.
L’applicazione (Client) in questo modo può usare, oltre ad un interfaccia standard per accedere alle factory, anche un interfaccia generica per usare i prodotti.
In sistemi interattivi spesso si vuole che delle azioni siano registrabili, annullabili o rieseguibili. Supponiamo che esistano più tipi di azioni (es. annulla digitazione; annulla cancellazione; ripeti cancellazione ecc). Se vogliamo che un applicazione usi in modo standard le operazioni eseguibili su queste operazioni possiamo creare una interfaccia generica Command che viene implementata dai comandi concreti. Tutte le operazioni vengono registrate all’interno di un Invoker ed eseguite su un Receiver (immaginiamo che un Invoker è la memoria del calcolatore e il Receiver è l’interfaccia grafica che visualizza i comandi effettuati). Tra Invoker e ConcreteCommandX, Receiver e ConcreteCommandX vi è delegazione in quanto ConcreteCommand deve avere la possibilità di comunicare al receiver l’esecuzione/annullamento di un comando. Un Invoker deve inoltre memorizzare la lista dei comandi.
Quando si ha a che fare con interfacce utente spesso si devono includere molte componenti grafiche all’interno di una finestra. Gestire le operazioni di ridimensionamento e spostamento senza alcun raggruppamento sarebbe una operazione complessa in quanto si dovrebbe interagire con molte componenti.
Ambienti per lo sviluppo di interfacce come Swing di Java utilizzano il composite design pattern. Le componenti grafiche vengono raggruppate in più Panel (es. parte superiore, centrale e inferiore di una finestra) lasciando ad ogni sottopannello il compito di gestire il layout delle componenti che contiene.
Nelle Swing alla radice della gerarchia di classi c’è un interfaccia Component che fornisce un comportamento generico per tutte le componenti grafiche (es. spostamento o ridimensionamento). Al di sotto di questa classe troviamo componenti come bottoni o label di testo e una particolare componente grafica Composite che rappresenta un contenitore di Component (es. può contenere bottoni, label, checkbox ecc).
Un panel ad esempio è un particolare Composite in cui è possibile inserire dei Button delle Label e qualsiasi altra classe che implementa Component. La strana relazione tra Component e Composite (ereditarietà + delegazione) è il cuore del composite design pattern e permette la realizzazione di interfacce grafiche complesse.
Un framework di applicazione è un’ applicazione parziale riusabile che può essere specializzata per produrre applicazioni personalizzate. A differenza delle librerie di classe i framework sono diretti a specifiche applicazioni (es: comunicazione cellulare o applicazioni real-time).
I framework contengono dei metodi hook (uncino) che devono essere implementati dalla specifica applicazione che si sta sviluppando.
I framework possono essere classificati in:
Esempi di questo tipo sono i sistemi operativi, debugger, interfacce utente (es Swing) che vengono inclusi in un progetto software ma non vengono presentati al cliente.
Vengono usati per integrare applicazioni distribuite con componenti (es RMI, CORBA).
Sono applicazioni specifiche che si focalizzano su particolari domini di applicazione (comunicazione cellulare o altro).
I framework possono inoltre essere classificati in base alle tecnologie usate per estenderli.
Per ottenere l’estensibilità si affidano all’ereditarietà e alla riscrittura di metodi hook.
L’estendibilità è affidata solo all’implementazione delle interfacce e all’integrazione di tali implementazioni usando la delegazione.
La principale differenza tra design pattern e framework è che i framework si focalizzano sul riuso degli algoritmi e sull’implementazione in un particolare linguaggio, mentre i patterns di focalizzano sul riuso di particolari strategie astratte.
Le librerie di classe sono il più generiche possibile e non si focalizzano su un particolare dominio di applicazione fornendo solo un riuso limitato mentre i framework sono specifici per un dominio o famiglia di domini.
Le componenti sono un raggruppamento di classi funzionanti anche da sole. Messe insieme, le componenti formano un’applicazione completa. In termini di riuso una componente è una scatola nera di cui non conosciamo l’implementazione ma solo alcune delle operazioni effettuabili su di esse. Le componenti offrono il vantaggio che le applicazioni le possono usare senza dover effettuare relazioni di ereditarietà.
Il riuso ha alcuni vantaggi tra cui:
Alcuni svantaggi del riuso sono:
La seconda fase dell’object design è la specifica delle interfacce. L’obbiettivodi questa fase è quello di produrre un modello che integri tutte le informazioni in modo coerente e preciso.
Questa fase è composta dalle seguenti attività:
Precedentemente abbiamo parlato di sviluppatori in modo generico. E’ possibile dividere gli sviluppatori in base al loro punto di vista.
Scrivono delle classi del sistema.
Usano classi già create da altri sviluppatori.
Estendono classi già create da altri sviluppatori.
La firma di un metodo è la specifica completa dei tipi di parametri che un metodo prende in input e di quelli presi in output.
La visibilità di un metodo può essere di tre tipi: Private, Protected, Public. In UML questi tre tipi si rappresentano rispettivamente con i simboli - # + fatti precedere alla firma del metodo o di un attributo.
Nel progettare le interfacce di classe bisogna valutare bene quali sono le informazioni da rendere pubbliche. Come regola bisognerebbe esporre in modo pubblico solo le informazioni strettamente necessarie.
Spesso l’informazione sul tipo di un attributo o parametro non bastano a restringere il range di valori di quell’attributo. Ai class user, implementor ed extendor serve condividere le stesse assunzioni sulle restrizioni.
I contratti possono essere di tre tipi:
E’ un predicato che è sempre vero per tutte le istanze di una classe.
Sono predicati associati ad una specifica operazione e deve essere vera prima che l’operazione sia invocata. Servono a specificare i vincoli che un chiamante deve rispettare prima di chiamare un operazione.
Sono predicati associati ad una specifica operazione e devono essere soddisfati dopo che l’operazione è stata eseguita. Sono usati per specificare vincoli che l’oggetto deve assicurare dopo l’invocazione dell’operazione.
Per esprimere contratti in modo più formale è possibile usare l’OCL. In OCL un contratto è una espressione che ritorna un valore booleano vero quando il contratto è soddisfatto.
Le espressioni hanno tutte questo template: context NomeClasse::firmaMetodo() tipoContratto: espressione
Per esprimere un contratto di classe e non di metodo si può omettere la firma del metodo e il doppio due punti dal template sopra (es. context NomeClasse pre: nomeAttributo = 0).
Nell’espressione è possibile usare nomi di metodi. (es. context Hashtable::put(key,value) pre: !containsKey(key) ).
Nelle espressioni di postcondizione è possibile indicare il valore restituito da un’operazione o il valore di un attributo prima della chiamata del metodo usando @pre.nomeMetodo() oppure @pre.nomeAttributo (es. context Hashtable::put(key,value) post: getSize() = @pre.getSize() + 1 ).
E’ possibile esprimere vincoli che coinvolgono più di una classe mettendo una freccia verso la classe che fa parte dell’espressione.
OCL così come è stato descritto, non permette espressioni che coinvolgono collezioni di oggetti. OCL mette a disposizione tre tipi di collezioni:
Insieme non ordinato di oggetti esprimibile con la forma {elemento1, elemento2, elemento3}
Insieme ordinato di oggetti esprimibile con la forma [elemento1, elemento2, elemento3]
Insiemi multipli di oggetti. La differenza con Sets è che gli oggetti possono essere presenti più volte o l’insieme può essere vuoto. (es. {elemento1, elemento2, elemento2, elemento3}
Per accedere alle collezioni, OCL fornisce delle operazioni standard usabili con la sintassi collezione->operazione(). Le più usate sono:
E’ possibile inoltre usare dei quantificatori come l’espressione collezione->forAll(condizione) che restituisce true se la condizione è vera per tutti gli elementi delle collezione,
oppure l’espressione collezione->exists(condizione) che restituisce true se esiste un elemento nella collezione che rispetta quella condizione.
E’ possibile usare un template per documentare l’Object Design che è il seguente:
1. Introduzione |
Esistono quattro tipi di trasformazioni:
Questo tipo di trasformazioni operano sul modello del sistema e non sul codice (es. convertire una stringa che rappresenta un indirizzo in una classe contenente i campi città, via, cap ecc).
L’input e l’output di questa trasformazione è il modello. Lo scopo di questa trasformazione è quello di ottimizzare o semplificare il modello originale. Una trasformazione di questo tipo potrebbe aggiungere rimuovere o rinominare classi, attributi, associazioni e operazioni .
I refactoring sono trasformazioni che operano sul sorgente. Effettuano un miglioramento del codice senza intaccare le funzionalità del sistema. Lo scopo di questa trasformazione è quello di aumentare la leggibilità e la modificabilità. Si focalizza sulla trasformazione di un singolo metodo o classe. Le operazioni di trasformazione, onde evitare di intaccare le funzionalità del sistema ed introdurre errori, vengono fatte eseguendo piccoli passi incrementali intervallati da test.
A partire da un modello ad oggetti produce un template di codice sorgente. Gli attributi e le operazioni possono essere mappate facilmente nel codice mentre il corpo dei metodi verrà aggiunto dagli sviluppatori.
Ogni attributo privato può essere mappato in un campo privato della classe più due metodi pubblici getAttributo e setAttributo rispettivamente per leggere e modificare l’attributo.
A partire dal codice si produce un modello del sistema. Questo viene fatto ad esempio quando il design del sistema viene perduto o quando non è mai stato creato.
Per evitare che le trasformazioni inducano in errori difficili da trovare e riparare, le trasformazioni dovrebbero seguire questi semplici principi:
Le attività riguardanti il mappaggio del modello sul codice coinvolgono tutte una serie di trasformazioni. Le trasformazioni che verranno trattate sono:
Quest’attività ha lo scopo di migliorare le performance del sistema. Questo può essere ottenuto riducendo la molteplicità delle associazioni per velocizzare le query.
Durante quest’attività mappiamo le associazioni in riferimenti o collezioni di riferimenti.
In questa fase descriviamo le operazioni che il sistema deve effettuare quando vengono rotti i contratti.
In questa attività mappiamo il modello delle classi in uno specifico schema di memorizzazione (es. definire le tabelle).
Le fasi di ottimizzazione sono le seguenti:
Se per richiedere una informazione bisogna attraversare troppe associazioni (es. metodo().metodo2().metodo3().metodo(4) ) bisognerebbe aggiungere un associazione diretta tra i due oggetti richiedente e fornitore.
Un’altra ottimizzazione può essere ottenuta riducendo le associazioni di tipo “molti” in “uno” oppure ordinando gli oggetti lato “molti” per velocizzare il tempo di accesso.
Gli attributi, nella fase di analisi, potrebbero essere stati collocati male nelle classi se vengono solo acceduti tramite i metodi get e set. Si potrebbero spostare direttamente nella classe che usa i metodi get e set per velocizzarne l’accesso.
Dopo le fasi di ottimizzazione alcuni oggetti potrebbero contenere pochi attributi e operazioni. In questi casi può essere utile trasformare queste classi in attributi semplici.
A volte caricare grosse quantità di dati che non vengono usati totalmente può essere inutile. Conviene, talvolta, caricare in memoria solo la parte di informazione che è strettamente necessaria e mettere il resto in una struttura temporanea.
Le associazioni viste nei diagrammi sono concetti astratti UML che nei linguaggi di programmazione tipo Java vengono mappate in riferimenti (nel caso di associazioni uno a uno) e collezioni (nel caso di associazioni uno-a-molti).
Se l’associazione tra due classi è uno-ad-uno unidirezionale, solo la classe che utilizza le operazioni dell’altra avrà il riferimento all’altra classe. Se invece l’associazione è uno-ad-uno bidirezionale ambedue le classi avranno un riferimento all’altra. Nel caso in cui l’associazione sia molti-a-molti si usano delle collezioni come liste, insiemi o tabelle hash.
Per quanto riguarda le classi di associazione viste in UML, queste possono essere mappate nel codice convertendole in normali classi e inserendo le classi dell’associazione come riferimenti.
Quando viene violato un contratto è buona norma che il sistema software lanci un eccezione. Lanciare un eccezione è un operazione che provoca un interruzione nel normale flusso del programma. Tale eccezione risale lo stack delle chiamate fino a quando non viene colta in qualche blocco di codice.
Le precondizioni vanno controllate prima dell’inizio del metodo e nel caso sia falsa va lanciata un eccezione. Le postcondizioni vengono controllate alla fine del metodo e deve essere lanciata un eccezione se non vengono soddisfatte. Le invarianti vanno controllate nello stesso momento delle postcondizioni.
E’ buona norma incapsulare il codice di controllo di un contratto in un metodo soprattutto se tale controllo deve essere effettuato da sottoclassi.
Alcune euristiche da seguire sono le seguenti:
Evitare il codice di controllo per le postcondizioni, invarianti, metodi privati e protetti e limitarlo su componenti di breve durata.
Gli oggetti vengono mappati in strutture dati che rispettano le scelte fatte nel system design (file o database). Se si scelgono i file bisogna scegliere uno schema di memorizzazione standard che non induca in ambiguità.
Le classi vengono mappate in tabelle che hanno lo stesso nome della classe e gli attributi vengono mappati in una colonna della tabella con lo stesso nome dell’attributo. Ogni riga della tabella corrisponde ad un’istanza della classe.
Nelle tabelle bisogna scegliere una chiave primaria che identifichi univocamente un’istanza della classe.
Per quanto riguarda le associazioni uno-ad-uno o uno-a-molti è necessario usare una chiave esterna che collega le due tabelle. Se l’associazione è uno-a-molti la chiave esterna è nella classe del lato “molti” in quanto si collega alla classe che la contiene, se è uno-ad-uno vengono mappate usando la chiave esterna in una qualsiasi delle due tabelle. Le associazioni molti-a-molti sono implementate usando una tabella aggiuntiva che ha due colonne contenenti le chiavi esterne delle tabelle relative alle classi in relazione.
E’ possibile mappare l’ereditarietà in due modi:
La superclasse e la sottoclasse sono mappate in tabelle distinte. La tabella della superclasse mantiene una colonna per ogni attributo definito nella superclasse e una colonna che indica quale tipo di sottoclasse rappresenta quell’istanza. La sottoclasse include solo gli attributi aggiuntivi rispetto alla superclasse e una chiave esterna che la collega alla tabella della superclasse.
Nel mapping orizzontale non esiste una tabella per la superclasse ma una tabella per ciascuna sottoclasse. In questo modo c’è ripetizione di attributi nel senso che tutte e due le tabelle avranno una colonna per ogni attributo contenuto nella superclasse.
I trade-off tra i due meccanismi riguardano la modificabilità e il tempo di accesso. Nella prima soluzione la modificabilità è più semplice in quanto aggiungere un attributo alla super classe richiede l’aggiunta di una colonna solo in una tabella e aggiungere una sottoclasse richiede di aggiungere una tabella che contenente solo gli attributi della sottoclasse. D’altra parte scegliere un mapping verticale porta ad una bassa efficienza in quanto caricare una sottoclasse dal database richiede l’accesso a due tabelle anziché una.
La soluzione di mapping orizzontale consente un più rapido accesso alle informazioni ma una più bassa modificabilità ed estensibilità.
Per scegliere una o l’altra soluzione bisogna trovare dei compromessi tra efficienza e modificabilità.
Nelle fasi di trasformazione ci sono vari ruoli che cooperano.
Il core architect seleziona le trasformazioni che devono essere applicate in maniere sistematica.
L’architecture liason è responsabile di documentare i contratti associati alle interfacce dei sottosistemi. Quando questi contratti cambiano è responsabile di comunicare i cambiamenti ai class user.
Lo sviluppatore deve seguire le convenzioni dettate dal core architect e convertire il modello in codice sorgente.
Il testing è l’attività che cerca le differenze tra le specifiche o i requisiti e il comportamento osservato.
Diamo ora alcune definizioni che verranno usate in seguito:
Misura della conformità del sistema con il comportamento osservato.
Probabilità che il sistema software non causi fallimenti per un certo tempo e sotto determinate condizioni.
Una deviazione del comportamento osservato rispetto a quello atteso.
Causa algoritmica o meccanica che ha portato a un comportamento errato.
Il sistema è in uno stato in cui qualsiasi operazione porta ad un fallimento.
Ci sono varie tecniche per aumentare l’affidabilità di un sistema software:
Questa tecnica prova a prevenire l’inserimento di errori nel sistema prima che lo stesso venga rilasciato.
Fanno parte di questa tecnica il debugging e il testing svolti durante la fase di sviluppo del software allo scopo di trovare errori. Questa tecnica non cerca di risolvere i difetti ma ha il solo scopo di identificarli (es. la scatola nera negli aeroplani).
Questa tecnica assume che un sistema può essere rilasciato con errori e che i fallimenti del sistema possono essere gestiti a runtime. In questi casi è possibile assegnare la stessa attività a più componenti che la eseguono contemporaneamente e alla fine confrontano il risultato ottenuto.
Per quanto riguarda il fault detection, abbiamo detto che ne fanno parte il testing e il debugging. Un aspetto molto importante del testing è la revisione (review).
La revisione è un controllo di parti o di tutti gli aspetti del sistema senza mandarlo in esecuzione. Ci sono due tipi di review:
Gli sviluppatori presentano il codice corredato di API e documentazione di una componente da testare al team di revisione. Il team di revisione commenta il codice aggiungendo dettagli riguardanti il mappaggio dell’analisi e del object design usando come spunto i casi d’uso e gli scenari della fase di analisi.
Un ispezione è simile al walkthrought ma la presentazione del codice non viene fatta dagli sviluppatori. Infatti il team di revisione controlla le interfacce e il codice delle componenti rispetto ai requisiti. Il team è anche responsabile di controllare l’efficienza degli algoritmi rispetto ai requisiti non funzionali e di controllare se i commenti inseriti sono coerenti rispetto al comportamento del codice.
Il debugging assume che un errore possa essere scovato partendo da un comportamento che non era stato previsto (es. se ci si accorge che una funzionalità non esegue bene il suo compito si inizia a fare debugging).
E’ una parte del sistema che può essere isolata per fare testing. Un componente può essere un oggetto, un gruppo di oggetti o uno o più sottosistemi.
E’ una manifestazione di un errore durante l’esecuzione del sistema (può essere causato da uno o più errori e può portare ad un fallimento).
I test stub e driver sono usati per sostituire e simulare parti mancanti del sistema.
E’ una particolare implementazione di una componente dal quale dipende una componente sotto testing.
E’ una particolare implementazione di una componente che fa uso della componente sotto testing.
E’ un insieme di input e un risultato atteso che potrebbero portare una componente a causare un fallimento. Un test case ha cinque attributi:
Un nome univoco rispetto ai test da effettuare
Descrive dove può essere trovato il programma che effettua il test.
Descrive l’insieme di comandi che devono essere immessi nel programma di test.
L’output che il programma dovrebbe dare.
Memorizza varie esecuzioni del test e determina le differenze tra il comportamento atteso e quello osservato.
I test case possono avere delle associazioni di aggregazione (un test case può essere composto di più sotto test) o precedenza (un test case deve essere eseguito prima di un altro).
Inoltre i test case possono essere classificati in whitebox e blackbox. Le blackbox si focalizzano solo sull’input e l’output del programma senza andare ad indagare nel codice, le whitebox si concentra sulla struttura interna della componente.
Una correzione è un cambiamento di una componente effettuato allo scopo di risolvere un errore. Una correzione potrebbe, in certi casi, indurre nuovi errori. Per evitare questo possiamo utilizzare alcune tecniche:
Mantiene traccia degli errori riscontrati e delle relative soluzione tramite una documentazione.
Vengono rieseguiti i test precedenti non appena viene corretta una componente.
Include una documentazione che specifica i motivi di un cambiamento o le motivazioni dello sviluppo di una componente.
Trova gli errori in singole componenti attraverso l’ispezione del codice sorgente. L’ispezione è condotta da un team di sviluppatori incluso l’autore della componente attraverso un meeting formale.
Un metodo proposto da Fagan è quello che divide l’ispezione in varie fasi:
L’autore della componente presenta le finalità della componente e gli obbiettivi dell’ispezione.
I revisori diventano familiari con l’implementazione della componente
Una persona legge il codice della componente e il team di ispezione elabora proposte. Un moderatore tiene traccia delle cose dette.
L’autore rivede e modifica la componente.
Il moderatore controlla la qualità della revisione e determina la componente che necessita di essere reispezionata
.
Speso le interfacce utente potrebbero risultare poco intuitive. Per questo motivo viene effettuato questo tipo di test. Gli sviluppatori determinano degli obbiettivi e osservano gli utenti sul campo prendendo nota del tempo che hanno impiegato per eseguire determinate operazioni e accettano eventuali commenti e suggerimenti.
Ci sono tre tipi di usability testing:
Viene presentato uno scenario agli utenti e viene valutato in quanto tempo gli utenti lo comprendono. E’ possibile usare anche dei mock-up.
Viene presentato un prototipo all’utente che rappresenta i punti chiave del sistema.
Il prototype testing è di tipo Vertical se implementa solo un caso d’uso, è Horizzontal se implementa un livello del sistema che coinvolge più casi d’uso.
Viene usata una versione funzionale del sistema e fatta visionare all’utente.
Nell’unit testing i singoli sottosistemi o oggetti vengono testati separatamente. Questo comporta il vantaggio di ridurre il tempo di testing testando piccole unità di sistema singolarmente. I candidati da sottoporre al testing vengono presi dal modello ad oggetti e dalla decomposizione in sottosistemi.
Gli unit testing possono essere divisi principalmente in due tipologie: whitebox testing e blackbox testing che sono due tipologie di analisi dinamica(diversa dall'analisi statica che controlla errori di sintassi etc.).
Per quanto riguarda il blackbox testing (test del comportamento dell'I/O) è possibile effettuarlo in due modi:
Gli input vengono divisi in classi di equivalenza. Ad esempio tutti gli input di numeri negativi e tutti gli input di numeri positivi.
Si selezionano degli input che sono limite per le classi di equivalenza (es. per i numeri positivi si testa il numero 1 o il più grande numero positivo rappresentabile).
Uno degli svantaggi delle tecniche di tipo blackbox è che non vengono testate combinazioni miste di input ma solo quelle interne alle classi di equivalenza.
Il whitebox testing (test dell'interno logico del sottosistema o oggetto) è diviso in quattro sottotipi:
Vengono testati i singoli statement del codice.
Vengono dati vari input che permettono di: saltare un ciclo, entrare in un ciclo e ripetere un ciclo più volte.
Viene costruito un diagramma di flusso del programma e si controlla se tutti i blocci del diagramma vengono attraversati. Vengono individuati dei test case che possano essere attraversati tutti i blocchi del programma.
Ci si assicura che ogni uscita di un istruzione condizionale sia testa almeno una volta (es. il blocco if o il blocco else devono essere attraversati almeno una volta).
L’utilità di questo testing è quello di rilevare errori che non sono stati rilevati con l’unit testing, Un piccolo gruppo di componenti realizzate vengono messe insieme. Non appena il piccolo sottoinsieme è perfettamente funzionante e non vengono evidenziati errori è possibile aggiungere componenti all’insieme.
Esistono varie strategie che decidono in che modo vengono scelti i sottoinsiemi di unità.
Le componenti vengono testate prima singolarmente e poi messe insieme in un unico sistema. Il vantaggio è che non è necessario sviluppare stub o driver per rendere funzionale un sottoinsieme. E’ però difficile, in sistemi complessi, individuare la componente responsabile di un errore.
Viene testata ogni componente del livello più basso, vengono integrate e successivamente unite con le componenti del livello superiore. In questo caso non è necessario avere dei test stub in quanto si inizia ad integrare dal livello più basso a salire. Un vantaggio di questa tecnica è che gli errori nelle interfacce grafiche vengono trovati subito in quanto, quando si testa l’interfaccia si ha già un sistema sottostante funzionante e ben definito.
Contrariamente al testing Bottom-up si inizia ad integrare le componenti del livello più alto e successivamente si intergrano quelle del livello inferiore. Non sono necessari test driver ma solo test stub per simulare le componenti inferiori. Uno dei problemi di questo tipo di testing è che è necessario scrivere molti stub.
Questa strategia combina bottom-up e top-down insieme cercando di usare il meglio di queste. Il sistema viene diviso in tre livelli: il livello target, un livello sopra il target e uno sotto. In questo modo possiamo effettuare il testing top-down e bottom-up in parallelo con lo scopo di arrivare ad integrare il target level. Un problema di questo testing è che le componenti non vengono testate separatamente prima di integrarle. Esiste infatti una modifica del sandwitch testing che testa le singole componenti prima di intergrarle.
Una volta che le componenti sono state integrate è testate prima con unit testing e poi integration testing è necessaria un fase di testing globale. Le attività di questa fase sono le seguenti:
Vengono controllate le differenze tra i requisiti funzionali e il sistema. I test case vengono presi dai casi d’uso. La differenza con usability testing è che mentre negli usability testing vengono trovate differenze tra il modello dei casi d’uso e le aspettative dell’utente, qui vengono trovate le differenze tra il modello dei casi d’uso e il comportamento osservato.
Questo test trova le differenze tra gli obbiettivi di design specificati e il sistema. Vengono effettuati i seguenti test:
Controlla se il sistema può rispondere a molte richieste simultanee.
Cerca errori quando il sistema elabora una grossa quantità di dati
Cerca di trovare falle nella sicurezza del sistema usando tipici errori di sicurezza.
Prova a valutare il tempo di risposta del sistema.
Valuta l’abilità del sistema di ripristinarsi dopo una condizione di errore.
Durante questo testing il sistema viene installato e fatto usare da una selezionata nicchia di utenti. Successivamente gli utenti vengono invitati a dare il loro feedback agli sviluppatori. Un alpha test è un test fatto nell’ambiente di sviluppo. Un beta test è un test fatto nell’ambiente di utilizzo.
L’utente può valutare in tre modi un test di acceptance:
Il cliente prepara una serie di test case su cui il sistema deve operare.
Il sistema viene confrontato e testato rispetto ad un altro sistema concorrente.
Viene testato il sistema legacy e il sistema attuale e gli output vengono messi a confronto.
Dopo che il sistema è stato accettato viene installato nel suo ambiente. In molti casi il test di installazione ripete i test case eseguiti durante il function testing e il performance testing. Quando il cliente è soddisfatto, il sistema viene formalmente rilasciato, ed è pronto per l’uso.
Fonte: http://www.unisasn.altervista.org/Riassunti%20di%20Ingegneria.doc
Sito web da visitare: http://www.unisasn.altervista.org/
Autore del testo: non indicato nel documento di origine
Il testo è di proprietà dei rispettivi autori che ringraziamo per l'opportunità che ci danno di far conoscere gratuitamente i loro testi per finalità illustrative e didattiche. Se siete gli autori del testo e siete interessati a richiedere la rimozione del testo o l'inserimento di altre informazioni inviateci un e-mail dopo le opportune verifiche soddisferemo la vostra richiesta nel più breve tempo possibile.
I riassunti , gli appunti i testi contenuti nel nostro sito sono messi a disposizione gratuitamente con finalità illustrative didattiche, scientifiche, a carattere sociale, civile e culturale a tutti i possibili interessati secondo il concetto del fair use e con l' obiettivo del rispetto della direttiva europea 2001/29/CE e dell' art. 70 della legge 633/1941 sul diritto d'autore
Le informazioni di medicina e salute contenute nel sito sono di natura generale ed a scopo puramente divulgativo e per questo motivo non possono sostituire in alcun caso il consiglio di un medico (ovvero un soggetto abilitato legalmente alla professione).
"Ciò che sappiamo è una goccia, ciò che ignoriamo un oceano!" Isaac Newton. Essendo impossibile tenere a mente l'enorme quantità di informazioni, l'importante è sapere dove ritrovare l'informazione quando questa serve. U. Eco
www.riassuntini.com dove ritrovare l'informazione quando questa serve